Kapitel 6. Dynamische Listen
Die Dynamische Liste ist in ReportServer das Mittel der Wahl, wenn es um schnelle, benutzerspezifische Auswertungen geht, oder der Fokus auf der anschließenden Weiterverarbeitung der Daten liegt.
Von der einfachen Selektion der Daten mittels Spaltenauswahl und Filter, über Sortierung, Gruppierung oder Zwischensummen, bis hin zu komplexen analytischen Funktionen kann mit der Dynamischen Liste nahezu jede Auswertungsanforderung abgebildet werden.
Einmal konfigurierte Auswertungen können als Variante im TeamSpace gespeichert und mit Kollegen gemeinsam verwendet werden.
Wenn Sie eine Dynamische Liste zur Ausführung geöffnet haben befinden Sie sich anschließend im Berichtsbereich, wo Sie Auswertung konfigurieren und schließlich ausführen können.
Grundlage einer jeden Dynamischen Liste ist eine von einem Administrator bereitgestellte Quelltabelle. Diese ist im Regelfall sehr umfangreich und kann leicht aus hunderten Spalten und mehreren Millionen Zeilen bestehen. Um Informationen aus diesen Daten zu gewinnen, ist es erforderlich eine Auswahl der zu betrachtenden Daten zu treffen. Zu diesem Zweck bietet ReportServer ein Vielzahl unterschiedlicher Werkzeuge, mit denen selbst komplexe Auswahlbedingungen intuitiv formuliert werden können.
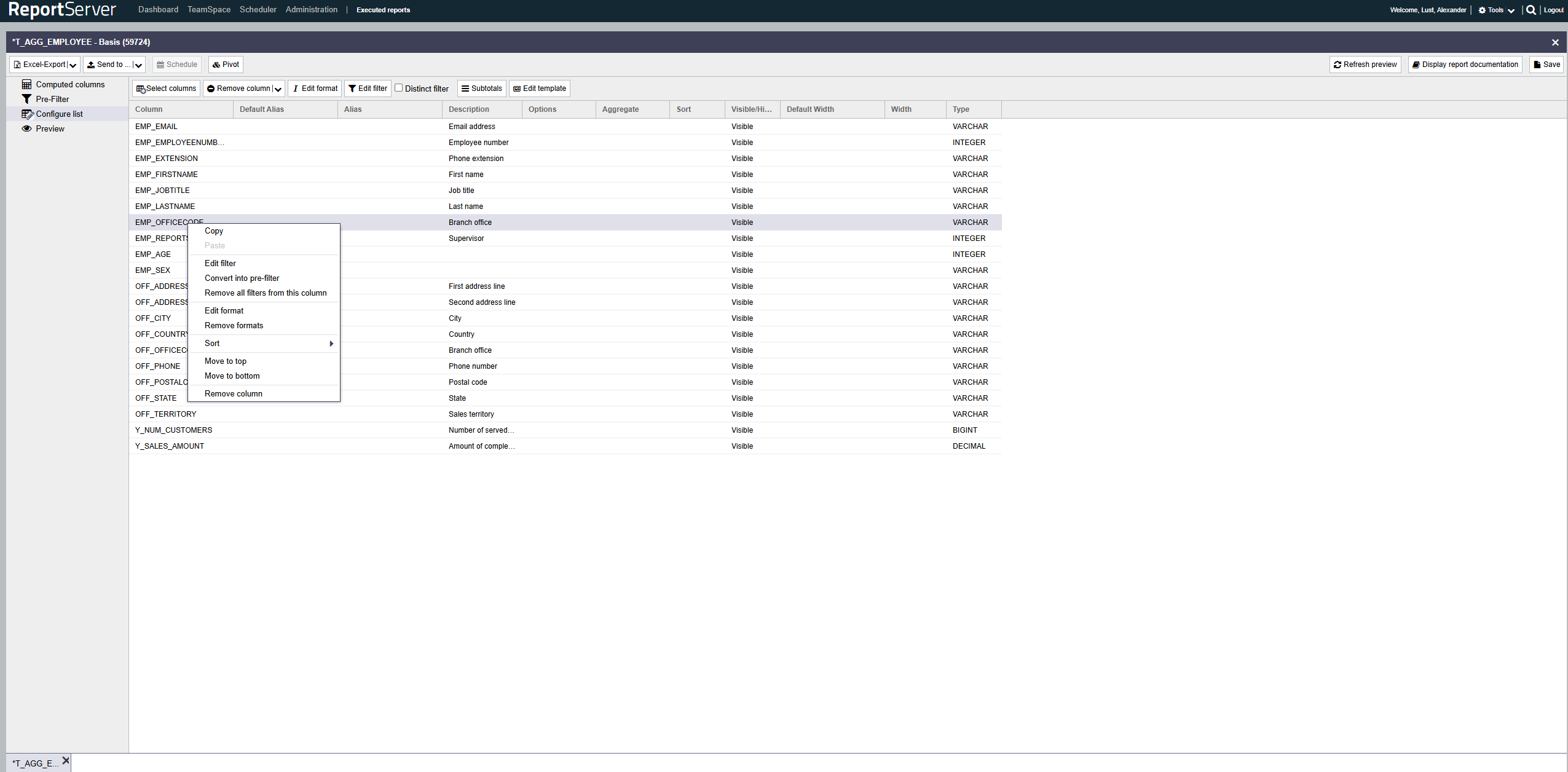
Der erste Schritt bei der Erstellung einer neuen Dynamischen Liste, ist die Auswahl der zu verwendenden Spalten. Die Spaltenauswahl erreichen Sie über die Werkzeugleiste des Aspekts . Diese öffnet den bereits bekannten Auswahldialog (vgl. Kapitel Erste Schritte). Im Dialogfeld werden Ihnen alle verfügbaren Spalten zur Auswahl angeboten.
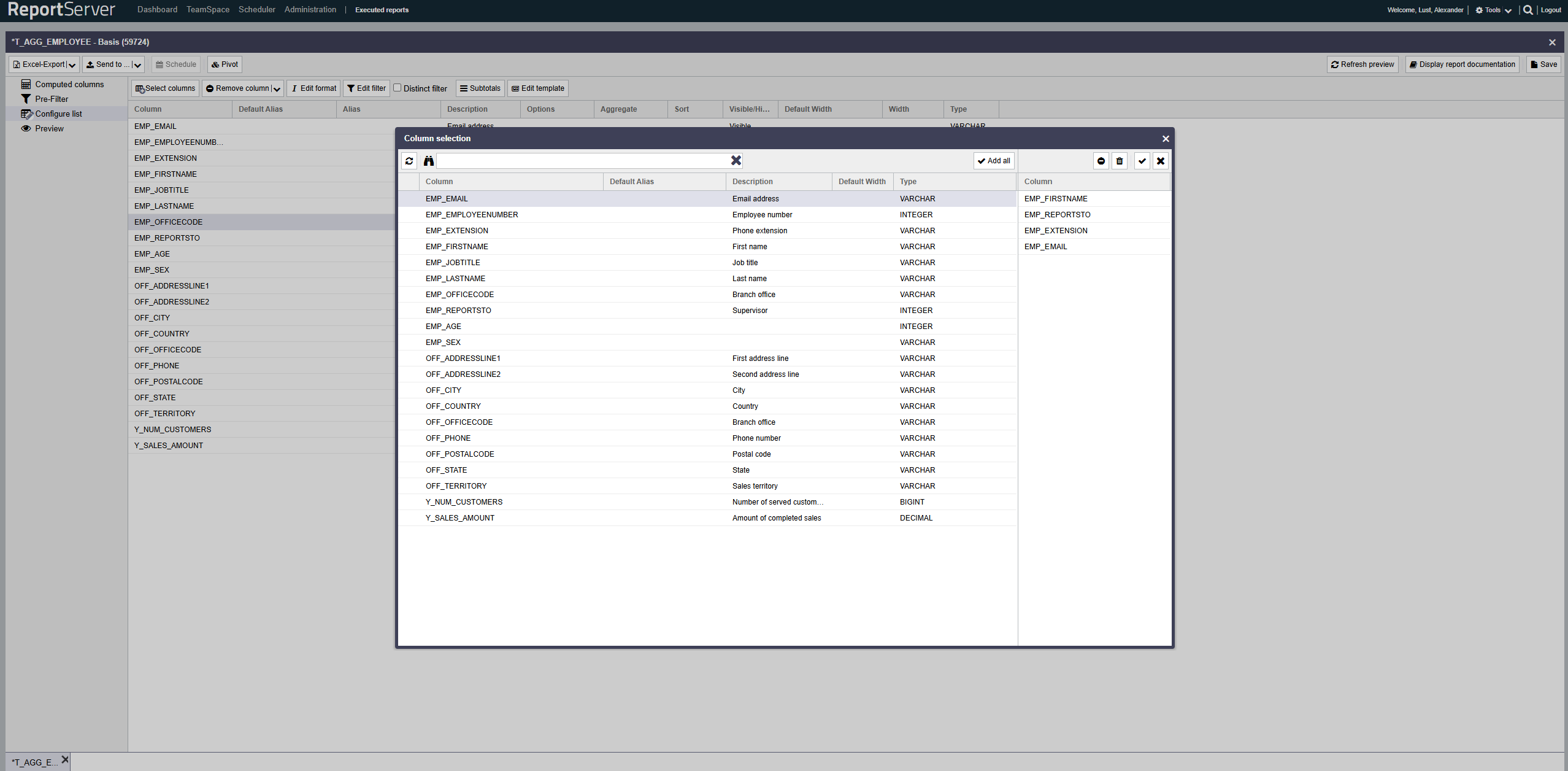
Die ausgewählten Spalten werden in den Aspekt übernommen.
Für jede ausgewählte Spalte werden die folgenden Informationen dargestellt:
| Spalte | Der technische Name der Spalte. |
| Vorgabe Spaltenname | Ein eventuell vorbelegter Klartextname. |
| Spaltenname | Hier können Sie einen eigenen Namen/Alias für die Spalte vergeben. |
| Beschreibung | Enthält, sofern verfügbar, eine Erläuterung zur Bedeutung der Spalte. |
| Optionen | Weist über Symbole auf die vorgenommene Konfiguration hin. |
| Aggregation | Erlaubt das Aggregieren auf dieser Spalte vgl. Abschnitt Aggregation. |
| Sortierung | Erlaubt es, die Daten nach dieser Spalte zu sortieren. |
| Versteckt | Über die Option , kann die Spalte ausgeblendet werden. |
| Type | Gibt den zu Grunde liegenden Datentyp an. |
Jeder Spalte in einer Datenbank ist ein fester Datentyp zugewiesen, welcher die Art der in dieser Spalte möglichen Inhalte bestimmt. Es gibt verschiedene Datentypen z.B. für Texte, Zahlen und Datumsangaben. Gängige Datentypen sind:
| VARCHAR | Text mit fester Maximallänge |
| INTEGER | Eine ganze Zahl |
| DOUBLE/FLOAT | Eine Fließkommazahl |
| DECIMAL | Eine Dezimalzahl |
| CLOB/BLOB | Beliebig langer Text / Binärdaten |
| DATE | Ein Datum evtl. incl. Uhrzeit |
Die Reihenfolge der Spalten im fertigen Bericht entspricht der Reihenfolge der Spalten in der Listenkonfiguration. Das Einstellen der Reihenfolge kann per Drag-and-Drop, oder über das Kontextmenü erfolgen.
Um die vom Bericht in der aktuellen Konfiguration zurückgegebenen Daten abzurufen, wechseln Sie in den Aspekt Vorschau. In der Vorschau werden Ihnen die ersten 50 Zeilen der von Ihnen konfigurierten Liste angezeigt. In der Werkzeugleiste der Vorschau (am unteren Rand) werden Informationen zu den ausgewählten Daten angezeigt. Diese umfassen neben der Anzahl der insgesamt verfügbaren Datensätze, Informationen zur Spaltenauswahl und Laufzeit. Die Laufzeitangabe ist geteilt in die reine Serverzeit und die Dauer der gesamten Anfrage. Über die Schaltflächen und kann durch das Ergebnis geblättert werden.
Per Doppelklick auf eine Zeile können Sie den ausgewählten Datensatz in einem neuen Fenster zur Detailansicht öffnen. Zum schnellen Anpassen der Konfiguration erreichen Sie viele Funktionen des Aspekts Listenkonfiguration auch über das Kontextmenü einer Datenzelle.
Um die Benennung einer Spalte zu ändern, können Sie in der Listenkonfiguration einen Alias vergeben. Klicken Sie hierzu unter Spaltenname in die entsprechende Zelle und vergeben Sie einen neuen Namen.
Je nach Konfiguration kann für eine Spalte ein Namensvorschlag hinterlegt sein. Dieser wird, sofern vorhanden in der Spalte angezeigt. Haben Sie einen eigenen Spaltennamen eingestellt, so überschreibt dieser die Vorgabe.
Die Sortierung der Datensätze im fertigen Bericht können Sie unterhalb von für jede Spalte einstellen. Wenn mehrere Spalten zu Sortierung konfiguriert sind, folgt die Priorität der Sortierung der Reihenfolge der Spalten.
In der Spalte können Sie einzelne Spalten von der Anzeige ausschließen. Dies ist nützlich, wenn Sie eine Spalte zur Filterung oder Sortierung nutzen möchten, diese jedoch nicht in der Anzeige enthalten sein soll.
Filter ermöglichen es Ihnen, die Daten des Berichts auf Zeilenebene zu beschränken, indem Sie Ein- und Ausschlusskriterien pro Spalte festlegen. Dieser Abschnitt behandelt die Grundlagen der Filterfunktion. Weitergehende Möglichkeiten, wie das Filtern mit Platzhaltern oder Formelausdrücken werden später in diesem Kapitel noch vorgestellt. Um eine Filterbedingung auf einer Spalte zu definieren, wählen Sie diese im Aspekt Listenkonfiguration aus und öffnen Sie den Filterdialog per Doppelklick oder über die entsprechende Schaltfläche in der Symbolleiste.
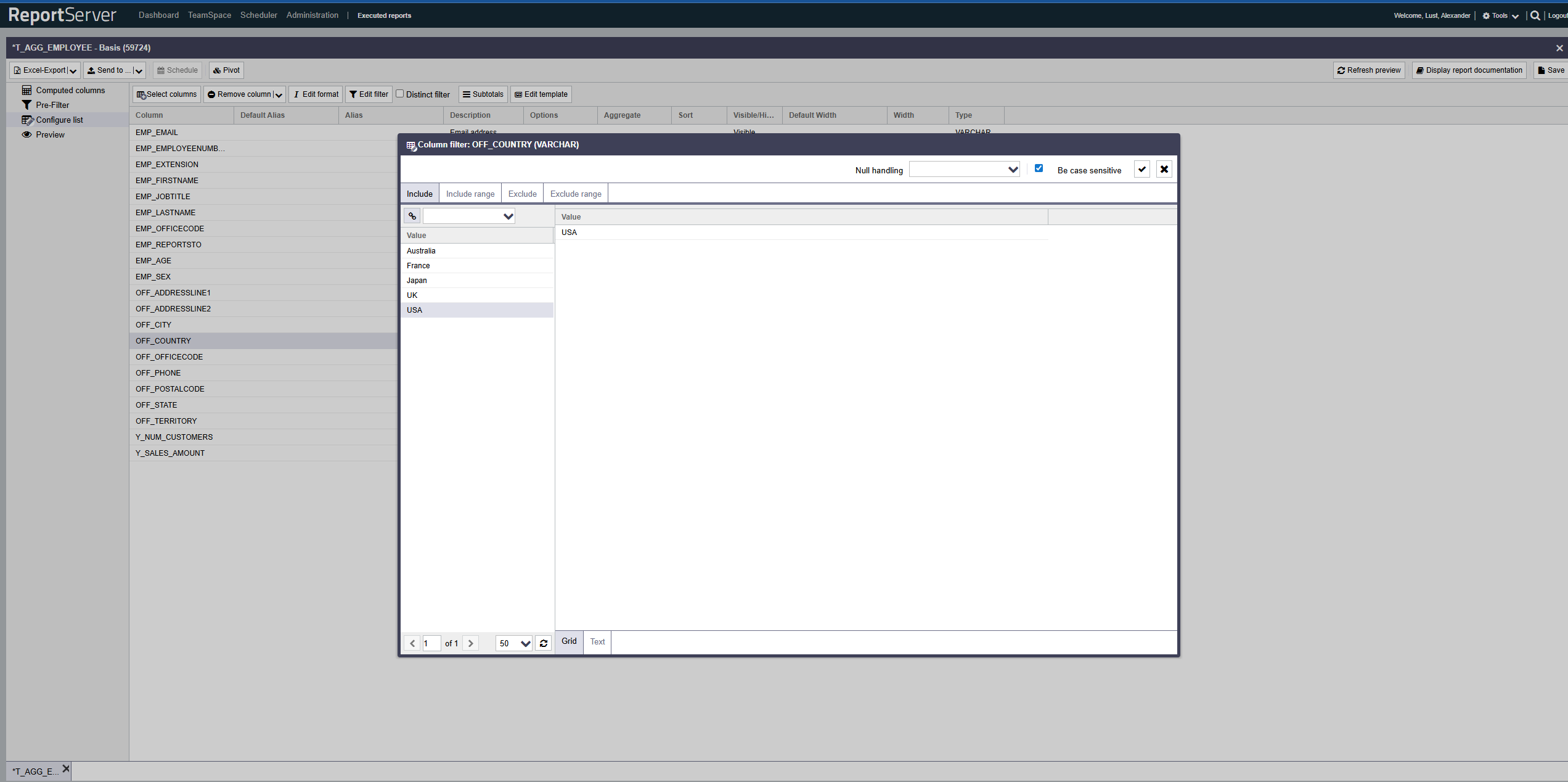
Zur Auswahl der zu berücksichtigen Datensätze, haben Sie, ausgehend von der Grundgesamtheit, zwei prinzipielle Möglichkeiten.
- Auswahl der zu berücksichtigenden Teilmenge: Diese Daten sind im fertigen Bericht enthalten (Einschluss)
- Auswahl der zu ignorierenden Teilmenge: Alle Daten, ausser den ausgewählten, sind im fertigen Bericht enthalten (Ausschluss)
Haben Sie sowohl Einschluss als auch Ausschluss definiert, so wirkt der Ausschluss nicht mehr ausgehend von der Grundgesamtheit, sondern ausgehend von den per Einschluss gewählten Datensätzen. Dies bedeutet insbesondere: Haben Sie einen einzelnen Wert explizit sowohl ein- als auch ausgeschlossen, so ist dieser in der Ergebnismenge nicht enthalten.
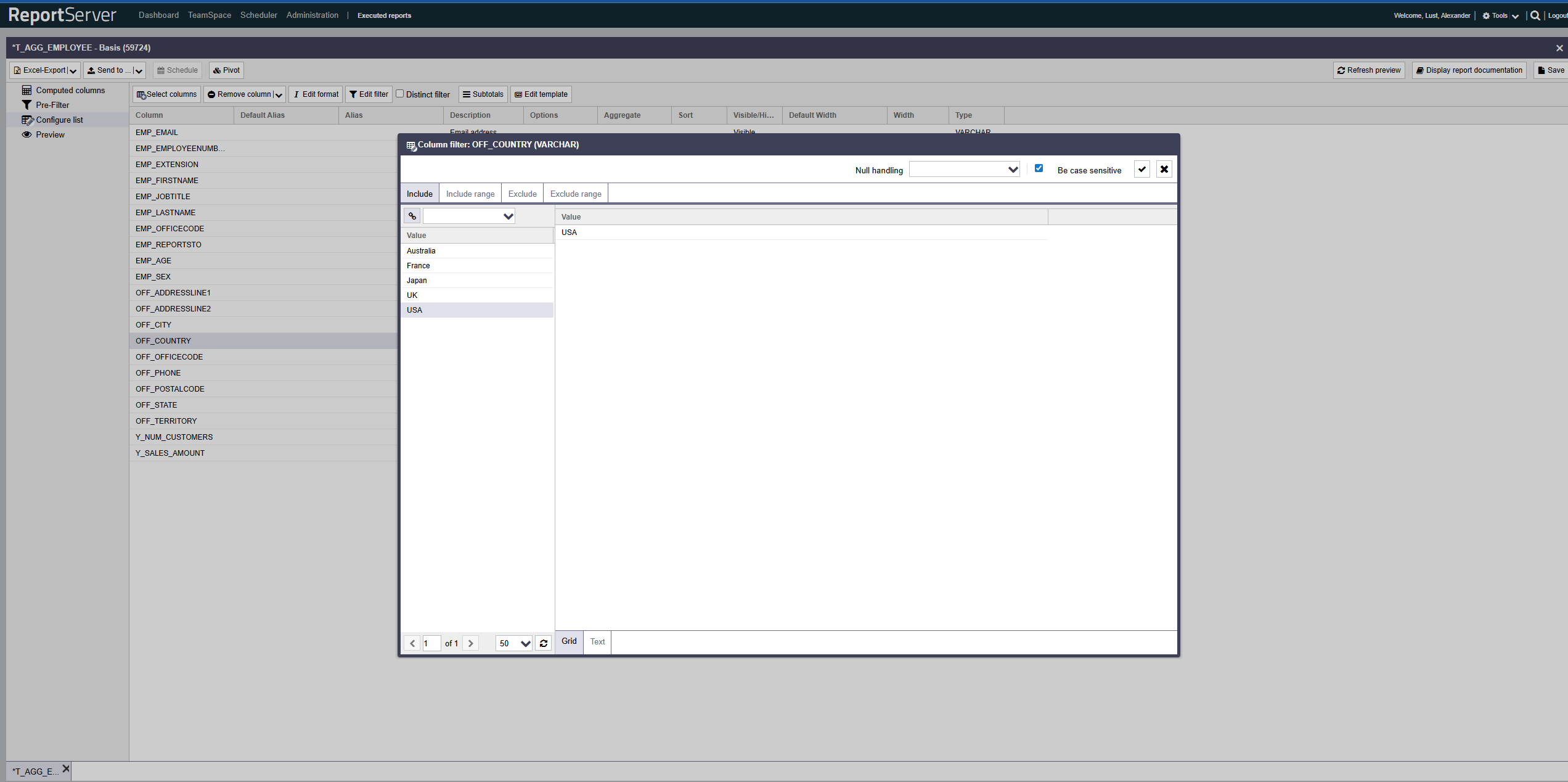
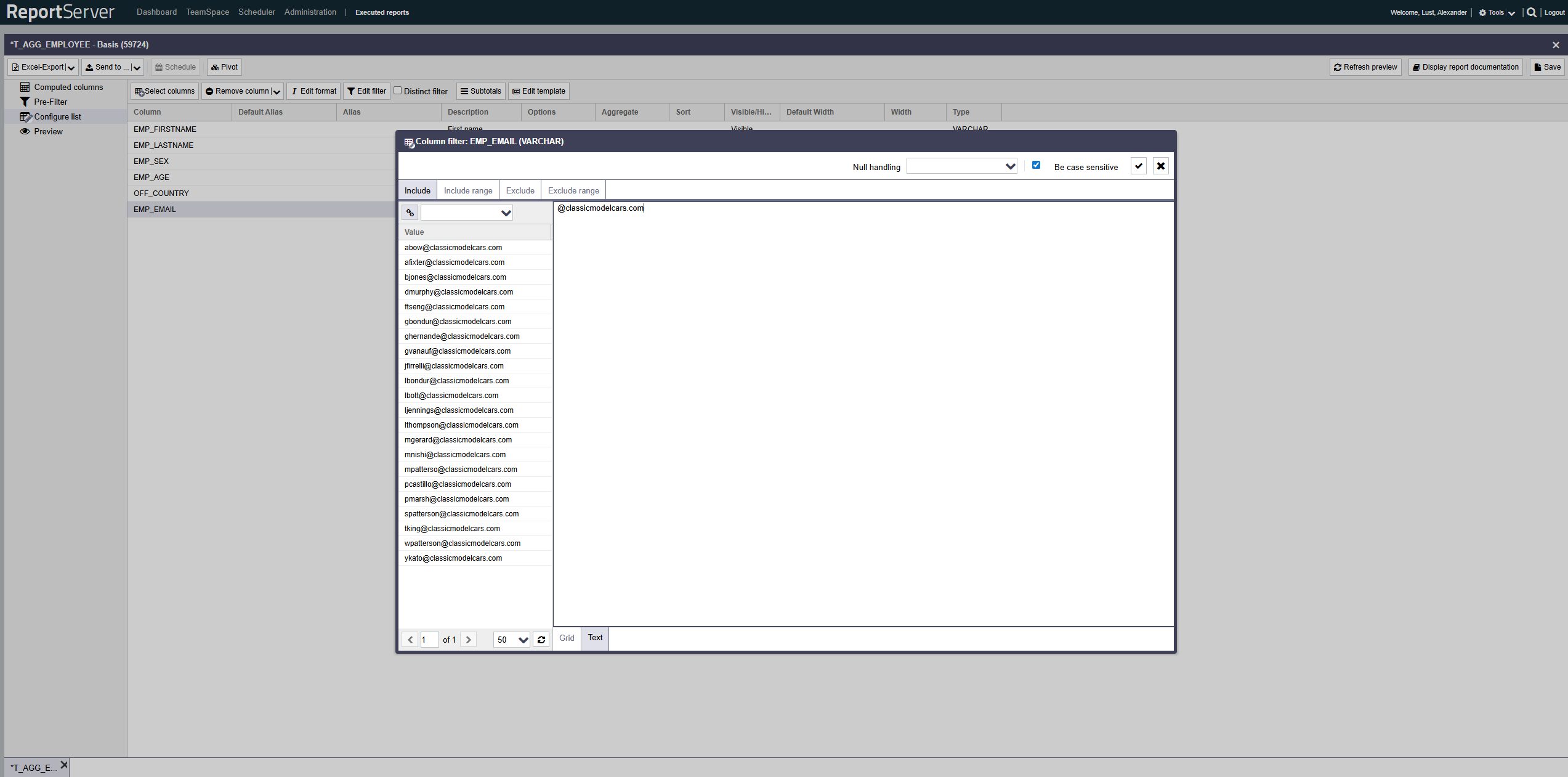
Der Filterdialog bietet die Möglichkeit Ein- und Ausschluss sowohl auf Basis von Einzelwerten als auch auf Wertebereichen zu definieren. Nutzen Sie hierzu die entsprechenden Registerkarten.
Der Aufbau der einzelnen Registerkarten ist hierbei prinzipiell gleich und ähnelt dem bereits bekannten Auswahldialog. Auf der linken Seite finden Sie die Werte der Spalte basierend auf der aktuell konfigurierten Grundgesamtheit, die durch andere Filter (sowohl auf der aktuellen, als auch auf anderen Spalten) bereits eingeschränkt sein kann.
Auch hier erfolgt die Übernahme von Werten in die Auswahl per Doppelklick oder Drag-and-Drop. Für den Ein- bzw. Ausschluss von Bereichen, werden jeweils zwei aufeinander folgende Auswahlen zu einem Bereich zusammengefasst (von A bis B).
Alternativ zur Auswahl von Werten können diese durch Umschaltung der Ansicht von Grid auf Text auch direkt eingegeben, bzw. aus der Zwischenablage (Copy & Paste) einfügen.
Bereiche werden im Textmodus als "A - B" eingegeben. Beachten Sie hierbei die Leerzeichen vor und nach dem Minus-Zeichen. Durch Auslassen einer der Bereichsgrenzen können Sie einen offenen Intervall definieren. Die Bereichsdefinition "Alle Werte größer als 5" würde geschrieben als "5 - ".
Um alle in der Spalte vorkommenden Werte, ungeachtet bereits konfigurierter Einschränkungen zu laden, klicken Sie auf das (Konsistenz erzwingen) neben dem Suchfeld. (Im Regelfall werden Sie diese Funktion nicht benötigen). Sie erlaubt es Ihnen Filter zu definieren, die mit der aktuellen Datengrundlage ein leeres Ergebnis produzieren würden, jedoch evtl. bei veränderten Ausgangsdaten trotzdem sinnvoll sind.
Standardmäßig wird bei der Filterung die Groß-/Kleinschreibung beachtet, d.h. der in den Daten vorkommende Wert muss exakt so geschrieben sein, wie Ihr Filterausdruck. Falls gewünscht, können Sie dies über die Option abschalten. Beachten Sie hierbei, dass das Ignorieren der Groß-/Kleinschreibung die Performance negativ beeinflussen kann.
Eine Besonderheit von Datenbanken, derer Sie sich beim Filtern bewusst sein sollten, ist die Behandlung von leeren Zellen. Unter einer leeren Zelle verstehen wir eine Zelle in der kein Wert vorhanden ist (im Datenbankjargon den Wert NULL haben). NULL ist insbesondere Verschieden von einem leeren String "" oder der Zahl 0.
Aufgrund dieser Besonderheit, dass NULL von jedem Wert verschieden ist, sind alle Zellen mit dem Wert NULL ausgeschlossen, sobald Sie irgendeinen Filter definiert haben. Insbesondere wenn nur ein Ausschlussfilter definiert ist, mag dies der Intuition zuwider laufen, ist jedoch in der relationalen Algebra, die die Grundlage aller gängigen Datenbanksysteme bildet üblich und daher auch in ReportServer so umgesetzt.
Für Sie bedeutet dies, dass Sie, sofern Sie Filter auf einer Spalte definiert haben, und auch leere Zellen in der Ergebnismenge enthalten sein sollen, Sie die leeren Zellen explizit mit einschließen müssen. Im Umkehrschluss gilt, dass das explizite Ausschließen leerer Zellen nur notwendig ist, wenn Sie ansonsten keine Filter auf dieser Spalte festgelegt haben. Die Behandlung leerer Zellen steuern Sie über die gleichnamige log.
Beachten Sie, dass auf Grund der Definition von Fließkommazahlen eine Überprüfung auf Gleichheit nur eingeschränkt möglich ist. Beim Filtern auf Spalten vom Typ Float oder Double sollten sie daher möglichst nur Bereichsfilter einsetzen. Statt einem Einschluss des Wertes 5,1 verwenden Sie z.B. einen Bereichsfilter 5,0009 - 5,1001.
Über die Option im Aspekt Listenkonfiguration unterdrücken Sie die Anzeige doppelter Datensätze in der Ergebnismenge. Eine Zeile gilt als doppelt, wenn Sie in allen sichtbaren Spalten mit einer anderen Zeile identisch ist.
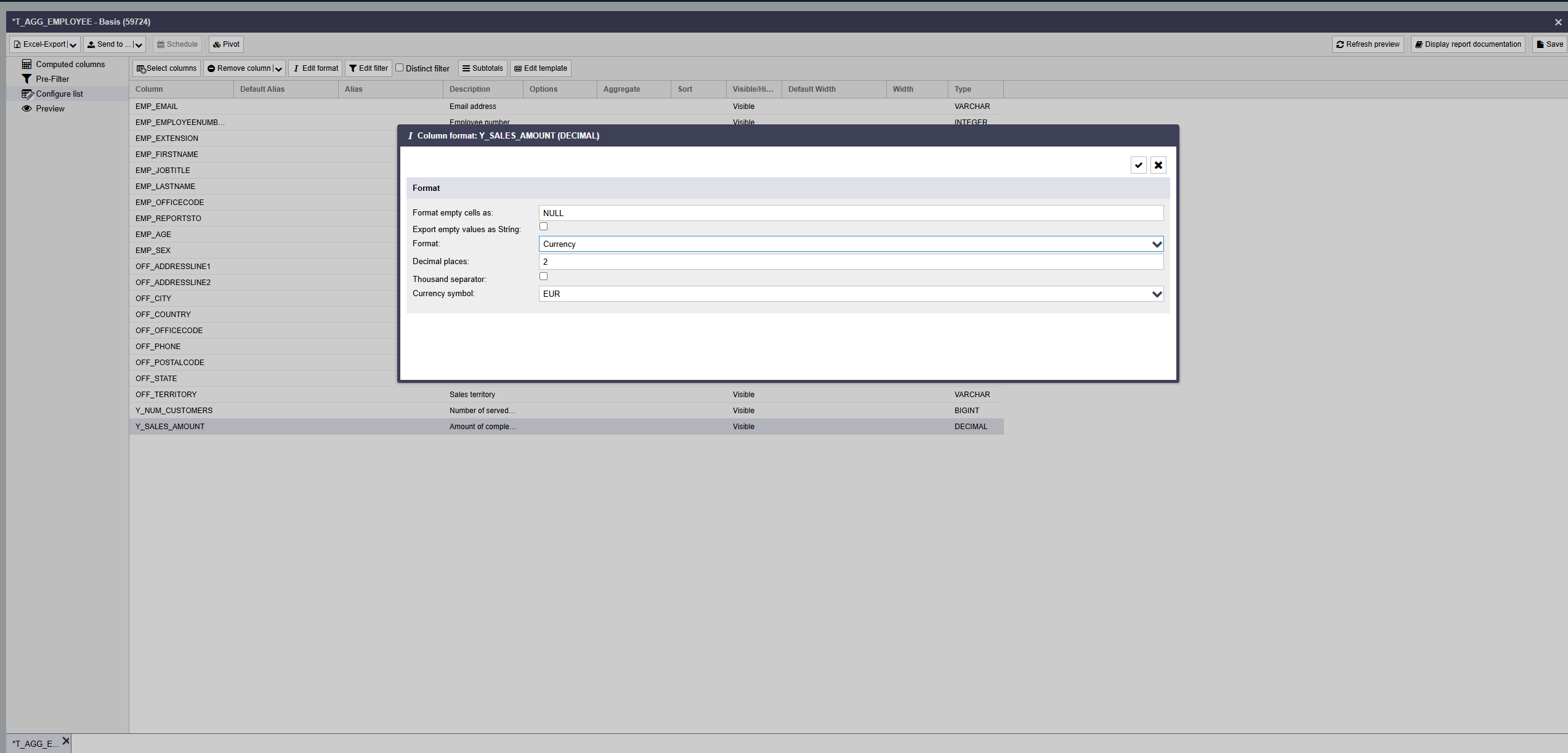
ReportServer erlaubt es Ihnen, direkt in der Listenkonfiguration für jede Spalte das gewünschte Ausgabeformat einzustellen. Selektieren Sie hierzu die gewünschte Spalte bzw. Spalten und wählen Sie die Schaltfläche Spaltenformat.
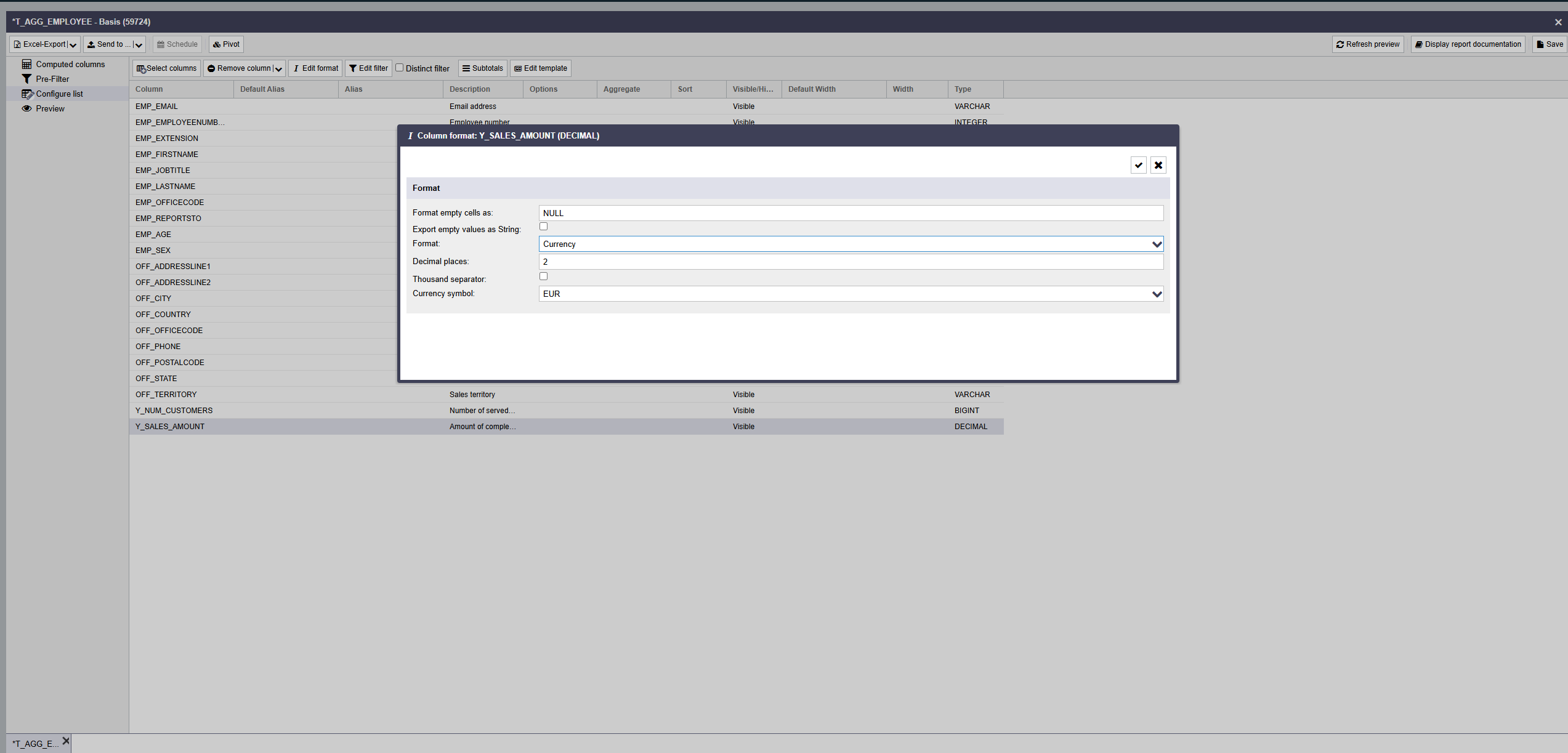
Im sich öffnenden Dialogfeld können Sie das zu verwendende Spaltenformat einstellen.
Je nach Datentyp der Spalte stehen die folgenden Formatierungsoptionen zur Verfügung:
| Zahl | Der Wert wird als Zahl interpretiert und mit der eingestellten Anzahl Dezimalstellen ausgegeben. Optional kann ein 1000er-Trennzeichen konfiguriert werden. |
| Prozent | Der Wert der Zelle wird als Prozentangabe interpretiert. |
| Wissenschaftlich | Zahlen werden ggF. in Exponentialschreibweise ausgegeben. |
| Währung | Der Wert wird als Zahl interpretiert und um das gewählte Währungssymbol erweitert. |
| Datum | Der Wert wird als Datum interpretiert und im angegebenen Zielformat ausgegeben. Sofern der Typ der zu Grunde liegenden Spalte kein Datumstyp ist, muss zusätzlich das Basisformat angegeben werden, in dem die Werte in der Datenbank vorliegen. Über die beiden Optionen ungültige Daten bereinigen sowie fehlerhafte Daten ersetzen kann in diesem Fall der Umgang mit Werten in der Datenbank eingestellt werden, die kein korrektes Datum repräsentieren. Zum Beispiel der 35.03.2012 oder "Letzen Dienstag". Ungültige Daten bereinigen errechnet im ersten Fall als effektives Datum den 04.04.2012 im zweiten Fall ist keine Bereinigung möglich. Mittels Fehlerhafte Daten ersetzen kann in dieser Situation ein Alternativwert vorgegeben werden. Hier kann auch ein ${}-Formelausdruck (vgl. Kapitel Formelsprache) angegeben werden, mit der Ersetzung "value" für den tatsächlich vorhandenen Wert. Die Definition von Ziel- und Basisformat entnehmen Sie der Tabelle Datumsformat in Anhang C. |
| Text | Der Wert wird als Text interpretiert - So bleiben z.B. führende Nullen erhalten. |
| Template | Erlaubt die Angabe eines ${}-Formelausdrucks der die Formatierung steuert (vgl. Kapitel Formelsprache. Die Ersetzung "value" enthält den vorhandenen Wert. |
Über die Schaltfläche öffnen Sie die Berichtsdokumentation. Diese fast übersichtlich alle vorgenommenen Einstellungen zusammen. Beachte Sie, dass sich die Berichtsdokumentation immer auf die zuletzt gespeicherte Version der Variante bezieht. In Abbildung finden Sie beispielhaft eine Berichtsdokumentation abgebildet. Für weitere Informationen zur Berichtsdokumentation lesen Sie auch den Abschnitt Berichtsdokumentation.

Im Filterdialog können Sie im Texteingabemodus zusätzlich zur exakten Angabe eines Wertes, mit Platzhaltern, sogenannten Wildcards arbeiten.
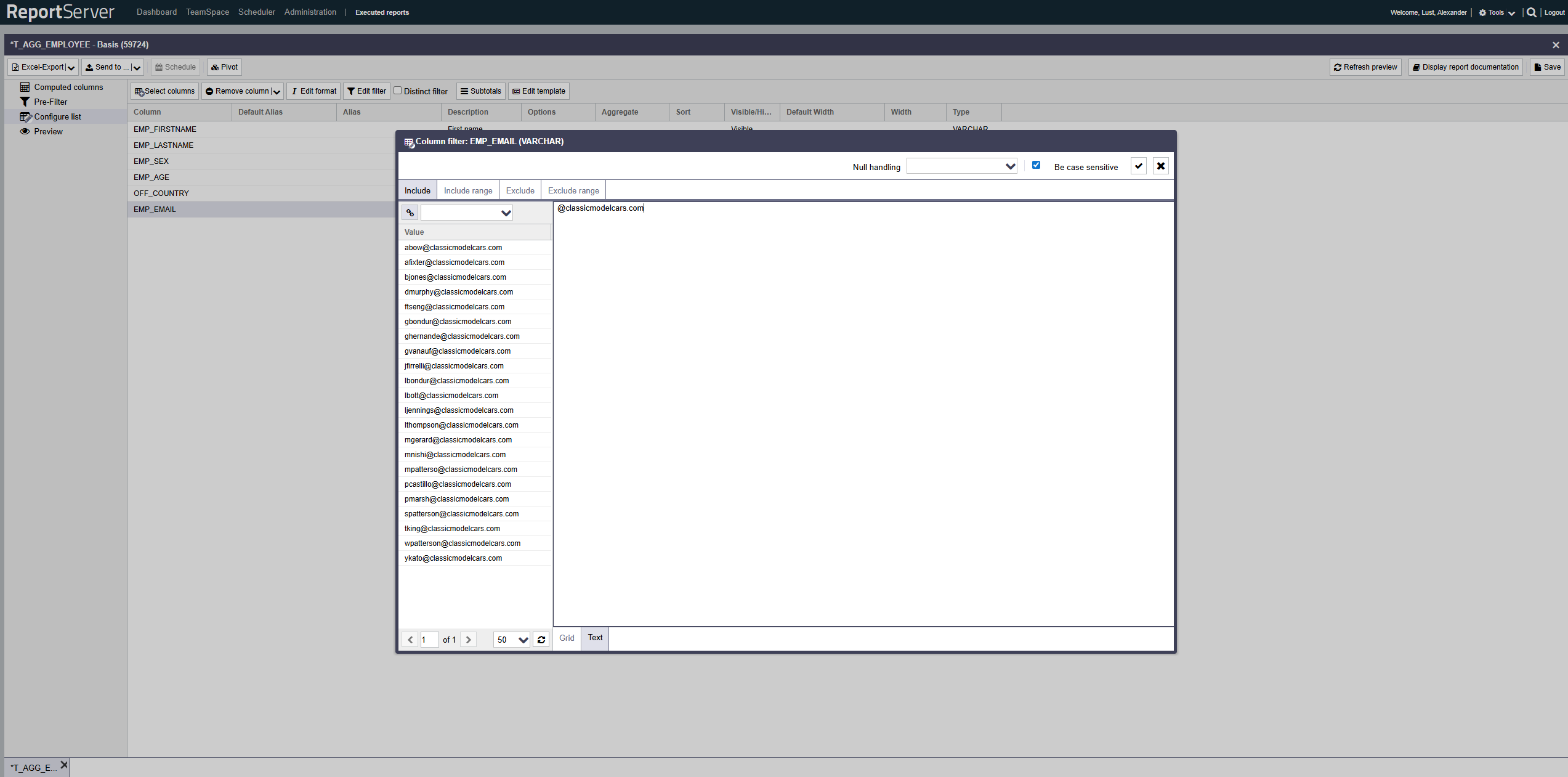
Der Platzhalter * steht dabei stellvertretend für eine Zeichenfolge beliebiger Länge. Dies schließt auch die leere Zeichenfolge mit ein. Beispiel: Dach* erfasst sowohl Dachboden, als auch Dachstuhl und Dach alleine.
Der Platzhalter ? hingegen bezeichnet genau ein beliebiges Zeichen.
Wildcards können auch in der Suchmaske des Filterdialogs verwendet werden.
Bei Wildcards in Bereichsfiltern wird der Bereich größtmöglich gewählt. Passt die durch das Wildcard beschriebene Maske auf mehrere Werte, so wird bei der unteren Intervallgrenze der kleinste passende Wert, für die obere Grenze der größte passende Wert gewählt.
Beachten Sie, dass wenn es für eine der Intervallgrenzen keinen dem Muster entsprechenden Wert gibt, das Intervall leer ist. Insbesondere beim Einschluss kann dies zu unerwarteten Problemen führen, z.B. a* - z* ist leer, wenn es keinen mit z beginnenden Wert gibt.
Aggregation bezeichnet das Zusammenfassen bzw. Verdichten von Daten, die bezüglich eines Gruppierungsmerkmals gleich sind und somit eine Gruppe bilden. Für jede in den Ausgangsdaten vorhandene Gruppe enthält die Ergebnismenge einen Datensatz.
Betrachten wir als Beispiel eine Liste von Personen mit den Merkmalen Geschlecht und Alter. Eine mögliche Aggregation wäre jetzt das Durchschnittsalter gruppiert nach Geschlecht. Hierbei wird eine Liste mit n Datensätzen verdichtet auf ein Ergebnis mit einer Zeile pro Geschlecht.
Bei der Aggregation unterscheiden wir somit zwischen Attributen, die festlegen, zu welcher Gruppe ein Datensatz gehört (Geschlecht) und solchen, die mit Hilfe einer Aggregatsfunktion zu einem einzelnen Wert zusammengefasst werden.
In ReportServer implementierte Aggregatsfunktionen sind:
| Durchschnitt | Berechnet den Durchschnittswert für ein Attribut. |
| Zählen | Gibt die Anzahl der Datensätze pro Gruppe an. |
| Maximum | Gibt den Maximalwert der Gruppe an. |
| Minimum | Gibt den Minimalwert der Gruppe an. |
| Summe | Berechnet die Summe aller Werte der Gruppe. |
| Varianz | Diese Funktion errechnet die Varianz. |
| Verschiedene Zählen | Wie Zählen, berücksichtigt jedoch nur unterschiedliche Werte des Attributs. |
Ist in ReportServer für eine Spalte eine Aggregatsfunktion eingestellt, so werden automatisch alle Spalten, ohne Aggregation, als Gruppierungsmerkmal betrachtet. Es ist nicht möglich, dass eine Liste Spalten enthält die weder Teil der Aggregation, noch der Gruppierung sind.
Um Aggregationen in Auswertungen zu nutzen, legen Sie im Aspekt Listenkonfiguration für einzelne Spalten/Attribute die zu verwendende Aggregatsfunktion fest.
Um bei Verwendung der Funktion Aggregation zusätzlich die zu Grunde liegenden Einzeldatensätze je Gruppe angezeigt zu bekommen, verwenden Sie die Funktion aus der Werkzeugleiste der Listenkonfiguration. Im sich öffnenden Dialogfeld wählen Sie aus den nicht aggregierten Spalten, die zur Gruppierung heranzuziehenden. Alle nicht ausgewählten und nicht aggregierten Attribute werden in den Einzeldatensätzen angezeigt.
Filter im Aspekt Listenkonfiguration wirken immer auf dem sichtbaren Endergebnis. Im Zusammenspiel mit der Funktion Aggregation bedeutet dies, dass zunächst aggregiert und anschließend auf dem Ergebnis gefiltert wird. In unserem Beispiel mit dem Durchschnittsalter bedeutet dies, dass ein Filter auf der Spalte Alter, das Durchschnittsalter im Ergebnis filtert jedoch nicht dazu geeignet ist einzelne Datensätze aus der Durchschnittsbildung auszuschließen.
Ein Filter auf der Spalte "Alter" mit der Definition "30 - " verändert somit nicht den Durchschnittswert der beiden Gruppen, sondern bewirkt, dass nur Gruppen mit einem Durchschnittswert größer oder gleich 30 angezeigt werden. Sollten Sie mit der Datenbanksprache SQL vertraut sein, so können Sie sich merken, dass Filter auf aggregierten Spalten als HAVING Filter umgesetzt werden.
Um abweichend vom hier beschriebenen Verhalten nicht das Ergebnis der Aggregation, sondern die in die Aggregation eingehenden Datensätze zu filtern, können Sie die nachfolgend beschriebene Funktion Vorfilter benutzen.
Vorfilter sind ein mächtiges Werkzeug um die Datenbasis einer Auswertung einzuschränken. Ihre Einsatzmöglichkeiten gehen dabei weit über die Filter im Aspekt Listenkonfiguration hinaus. Die drei Hauptunterschiede sind:
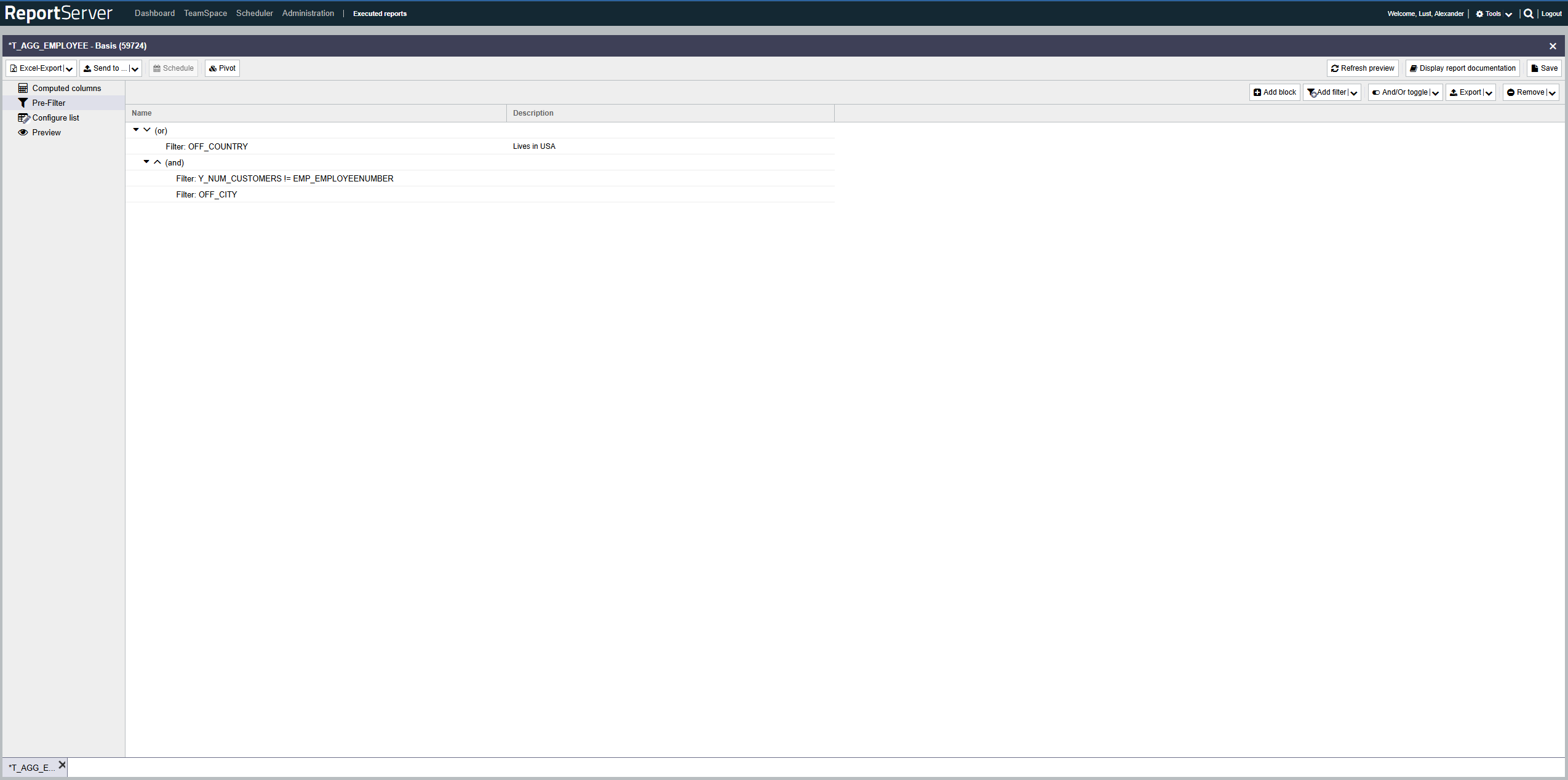
Filter mit Oder-Verknüpfung Während alle Filter in der Spaltenkonfiguration UND-Verknüpft sind, ein Datensatz also genau dann in der Ergebnismenge enthalten ist, wenn dieser die Filterbedingungen aller Spalten erfüllt, so kann im Vorfilter eine beliebige Kombination von UND und ODER Ausdrücken zur Verknüpfung der Filterbedingungen verschiedener Spalten definiert werden.
Spaltenvergleich Der Spaltenvergleich erlaubt es ein Filterkriterium zu definieren, dessen Grundlage die Relation zweier Attribute eines Datensatzes ist. Als Beispiel könnten etwa alle Datensätze ausgewählt werden, bei denen der Wert in Spalte A vom Wert in Spalte B verschieden ist.
Filterung vor Aggregation Wie im vorhergehenden Abschnitt beschrieben wirken die Filter der Listenkonfiguration immer auf dem sichtbaren Ergebnis. Im Zusammenspiel mit der Aggregation bedeutet dies, dass Filter erst nach der Aggregation wirken. Vorfilter hingegen wirken immer vor der Aggregation. Ist keine Aggregation konfiguriert besteht in dieser Hinsicht zwischen Vorfiltern und den Filtern der Listenkonfiguration kein Unterschied.
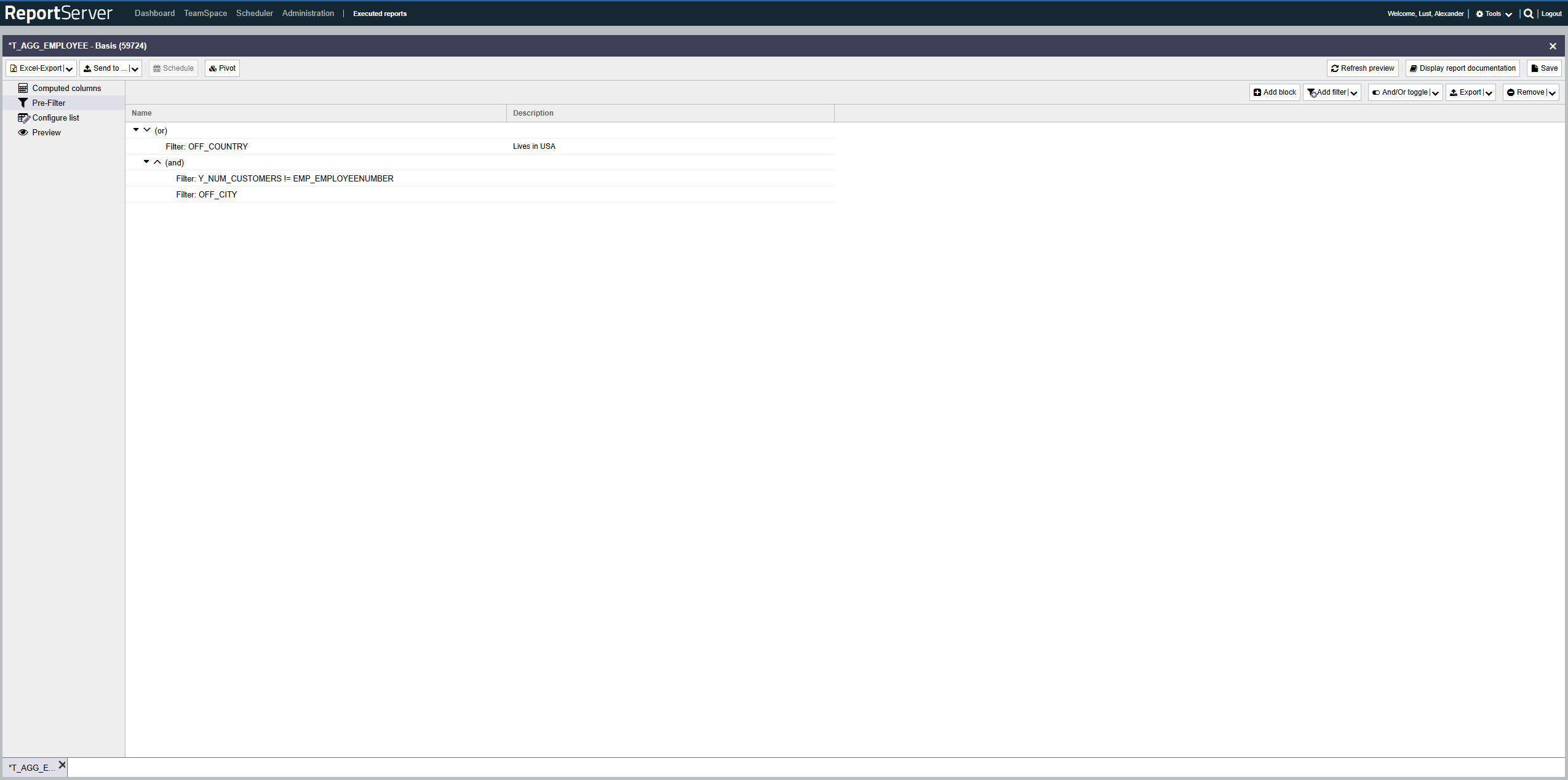
Der Vorfilter enthält eine Menge von Filterausdrücken welche mit UND und ODER kombiniert und beliebig verschachtelt werden können.
Betrachten wir ein Beispiel mit folgenden vier Filtern
A := Alter > 30
B := Geschlecht == weiblich
C := Wohnort == Berlin
D := Alter < 5
E := Geburtsort == Wohnort
Die Verbindung dieser Einzelfilter zu folgenden kombinierten Ausdruck
(B UND C UND (A ODER D ODER E))ReportServers Vorfilter stellt einen solchen Ausdruck als Baum, wie folgt dar:
| UND | B | |
| C | ||
| ODER | A | |
| D | ||
| E | ||
UND und ODER stellen hierbei Blöcke dar, die die darunterliegenden Ausdrücke umschließen. Der UND-Block im Beispiel beinhaltet also B, C sowie den ODER-Block. Der ODER-Block wiederum beinhaltet A sowie D und E.
Bei der Auswertung des Baumes, werden zuerst für jeden Datensatz die einzelnen Filter (A, B, C, D, E) ausgewertet. Das Ergebnis einer jeden solchen Auswertung liefert einen Wahrheitswert: WAHR, oder FALSCH.
Beispiel-Datensatz:
Alter = 25
Geschlecht = Weiblich
Wohnort = Berlin
Geburtsort = Stuttgart
Wertet man die eingangs genannten Filterbedingungen A bis E gegen diesen Beispieldatensatz aus so erhält man folgendem Baum:
| UND | WAHR | |
| WAHR | ||
| ODER | FALSCH | |
| FALSCH | ||
| FALSCH | ||
Im folgenden Schritt werden die Wahrheitswerte von Blöcken bestimmt. Dazu werden die Wahrheitswerte aller Blöcke, die keine weiteren Blöcke beinhalten mit der Logischen Operation des Block kombiniert.
Ein UND-Block ist genau dann WAHR, wenn alle umschlossenen Ausdrücke WAHR sind. Ein ODER-Block ist WAHR, wenn mindestens einer der umschlossenen Ausdrücke WAHR ist.
Der Block wird anschließend durch seinen Wahrheitswert ersetzt. Dieser Vorgang wird solange wiederholt, bis der Wurzelblock bestimmt ist.
Im Beispiel geschieht dies in zwei Schritten:
| UND | WAHR |
| WAHR | |
| FALSCH | |
| FALSCH |
Somit ist der Beispieldatensatz nicht Teil der Ergebnismenge.
Über die Werkzeugleiste fügen Sie Blöcke und Filter zu Ihrem Ausdruck hinzu. Diese werden jeweils unterhalb (als Teil) des aktuell ausgewählten Blockes eingefügt. Blöcke und Filter können per Drag-and-Drop auf einen anderen Block geschoben werden. Die Reihenfolge von Ausdrücken innerhalb eines Blockes ist unerheblich. UND-Blöcke können direkt nur ODER-Blöcke und ODER-Blöcke nur UND-Blöcke beinhalten. Beim Einfügen neuer Blöcke, bzw. beim Verschieben wird automatisch der korrekte Typ gewählt.
Die schon mehrfach erwähnte $-Formelsprache kann auch im Filterdialog verwendet werden. Anstatt eines Wertes können Sie im Textmodus eine beliebige Formel angeben. In den Formeln stehen Ihnen im Filter, zusätzlich zu den Standardersetzungen (vgl. Formelsprache), folgende weitere Objekte/Ersetzungen für eigene Berechnungen zur Verfügung:
| today | Ein Kalenderobjekt, mit dem ausgehend vom aktuellen Datum Berechnungen durchgeführt werden können. Z.B. ein Bereichsfilter der alle Rechnungen der letzten 7 Tage findet. |
| agg | Bietet Zugriff auf Berechnungen über allen Werten der aktuellen Spalte. Dies kann z.B. genutzt werden, um Ausreißer zu identifizieren. |
| analytical | Gestattet den Zugriff auf analytische Funktionen. Es kann zum Beispiel ein Filter definiert werden, der die Top 10% einschließt. |
Das today Objekt bietet Zugriff auf einen vollständigen Kalender. Dieser Kalender ist zu Beginn mit dem aktuellen Datum und der aktuellen Uhrzeit der Ausführung initialisiert. Mit den nachfolgenden Funktionen können Sie das Datum, bzw. die Uhrzeit die im Kalender hinterlegt ist manipulieren.
| firstDay | Setzt den Kalender auf Mitternacht (0 Uhr) des ersten Tages des aktuellen Monats. |
| lastDay | Setzt den Kalender auf die letzte Sekunde des letzten Tages des aktuellen Monats. |
| addDays | Setzt den Kalender die angegebene Zahl an Tagen weiter/zurück. |
| addMonths | Setzt den Kalender die angegebene Zahl an Monaten weiter/zurück. |
| addYears | Setzt den Kalender die angegebene Zahl an Jahren weiter/zurück. |
| setDay | Setzt den Kalender auf den angegebenen Tag. |
| setMonth | Setzt den Kalender auf den angegebenen Monat. |
| setYear | Setzt den Kalender auf das angegebene Jahr. |
| clearTime | Setzt die Uhrzeit auf Mitternacht zurück. |
| addHours | Setzt den Kalender die angegebene Zahl an Stunden weiter/zurück. |
| addMinutes | Setzt den Kalender die angegebene Zahl an Minuten weiter/zurück. |
| addSeconds | Setzt den Kalender die angegebene Zahl an Sekunden weiter/zurück. |
| setHours | Setzt die Uhrzeit auf die angegebene Stunde. |
| setMinutes | Setzt die Uhrzeit auf die angegebenen Minuten. |
| setSeconds | Setzt die Uhrzeit auf die angegebenen Sekunden. |
| format | Diese Funktion wandelt das Datum in einen Text im angegebenen Format. Dies ist notwendig, um Vergleiche auf Spalten vorzunehmen die nicht vom Typ Datum sind (vgl. Tabelle Datumsformat in Anhang C.). |
Beispiel: Sie möchten alle Rechnungen des vergangenen Monats filtern. Dazu können Sie folgenden Einschlussfilter definieren:
${today.firstDay().addMonths(-1)} - ${today.firstDay().addSeconds(-1)}
Sollte die Spalte vom Typ VARCHAR sein (also eine Textspalte) und das Format in der Form Tag.Monat.Jahr angegeben sein, so müssen Sie die Formelausdrücke um den Aufruf der format-Funktion erweitern:
${today.firstDay().addMonths(-1).format("dd.MM.yyyy")}
-
${today.firstDay().addSeconds(-1).format("dd.MM.yyyy")}Das agg-Objekt bietet Zugriff auf Berechnungen über alle Werte der aktuellen Spalte. So kann beispielsweise ein Filterausdruck, der sich auf den Durchschnittswert der Spalte bezieht, definiert werden.
Es stehen folgende Funktionen zur Verfügung:
| avg | Diese Funktion errechnet den Durchschnitt. |
| count | Diese Funktion zählt die vorhandenen Werte. |
| countDistinct | Diese Funktion zählt die vorhandenen unterschiedlichen Ausprägungen. |
| sum | Diese Funktion summiert alle Werte der Spalte. |
| variance | Diese Funktion berechnet die Varianz der Spalte. |
| max | Diese Funktion ermittelt den Maximalwert der Spalte. |
| min | Diese Funktion ermittelt den Minimalwert der Spalte. |
Ähnlich dem agg-Objekt erlaubt das analytical-Objekt Filter einer Spalte ausgehend von einer Berechnung über alle Werte der Spalte zu definieren. Im Gegensatz zum agg-Objekt, das immer nur einen einzelnen Wert zurückgibt, liefert das analytical-Objekt eine Menge an Werten zurück. Das analytical-Objekt kann somit nur in Werte, nicht jedoch in Bereichsfiltern benutzt werden.
Folgende Funktionen werden durch das analytical Objekt bereitgestellt:
| top(n) | Gibt die größten n Werte der Spalte zurück. |
| bottom(n) | Gibt die kleinsten n Werte der Spalte zurück. |
| topGrouped (n,'Spaltenname') | Gibt die größten n Werte der Spalte, gruppiert nach der Spalte Spaltenname zurück. |
| bottomGrouped (n,'Spaltenname') | Gibt die kleinsten n Werte der Spalte, gruppiert nach der Spalte Spaltenname zurück. |
Bei Angabe einer ganzen Zahl für n wird die Angabe als Anzahl der zurückzugebenden Wert interpretiert. Eine Dezimalzahl im Bereich 0 bis 1 wird als Prozentangabe aufgefasst. So bezeichnet top(0.1) die oberen 10%.
Bei den beiden Grouped-Funktionen müssen Sie zusätzlich den Namen einer Spalte angeben. Nach dieser wird der Bericht zunächst gruppiert. Danach werden die Top- oder Bottom-Werte ermittelt.
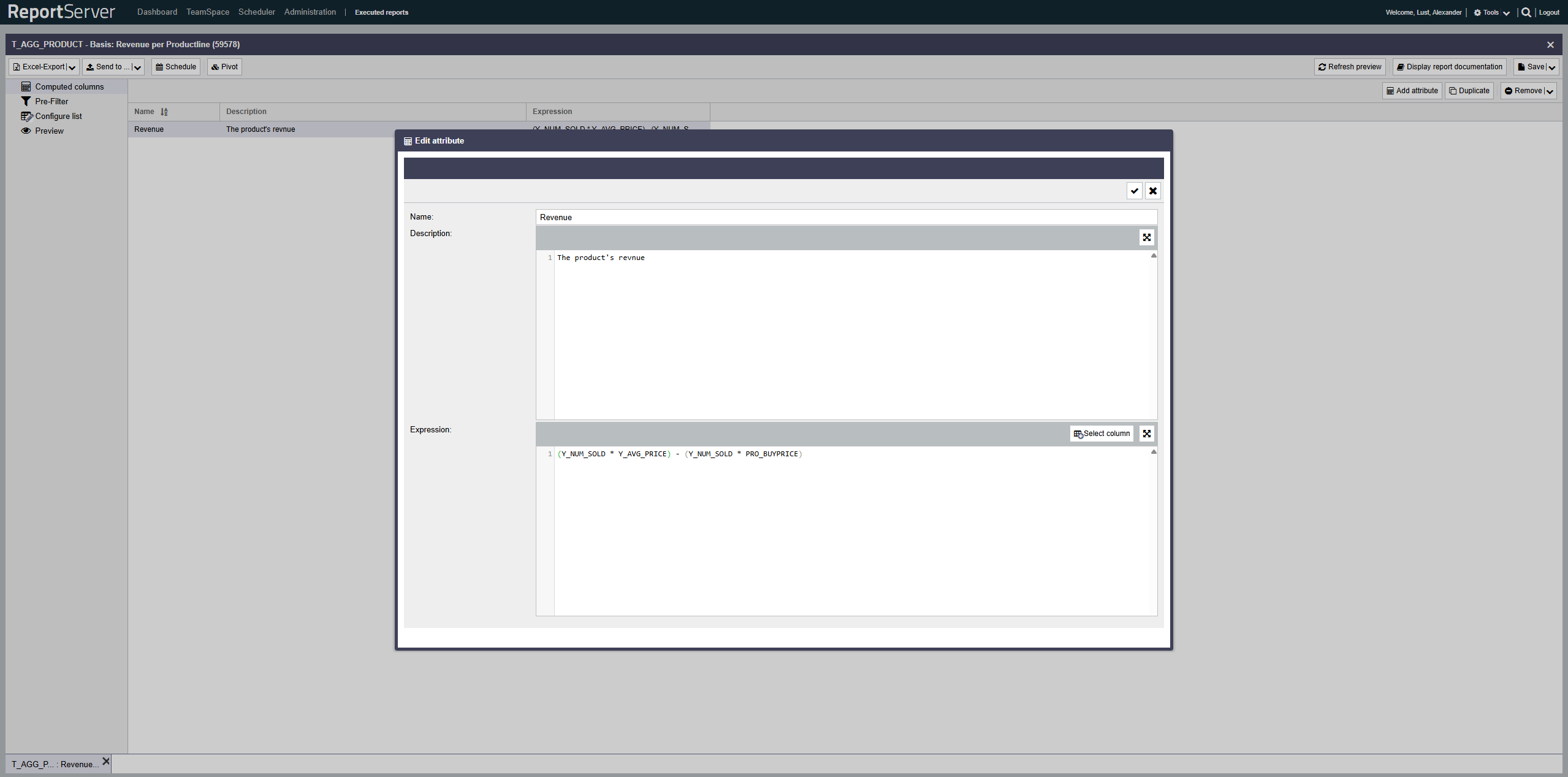
Berechnete Felder erlauben es Ihnen Ihre Auswertung um Spalten zu erweitern, die zwar nicht in den Quelldaten vorkommen, sich jedoch durch eine Berechnungsvorschrift aus den vorhandenen Spalten ergeben.
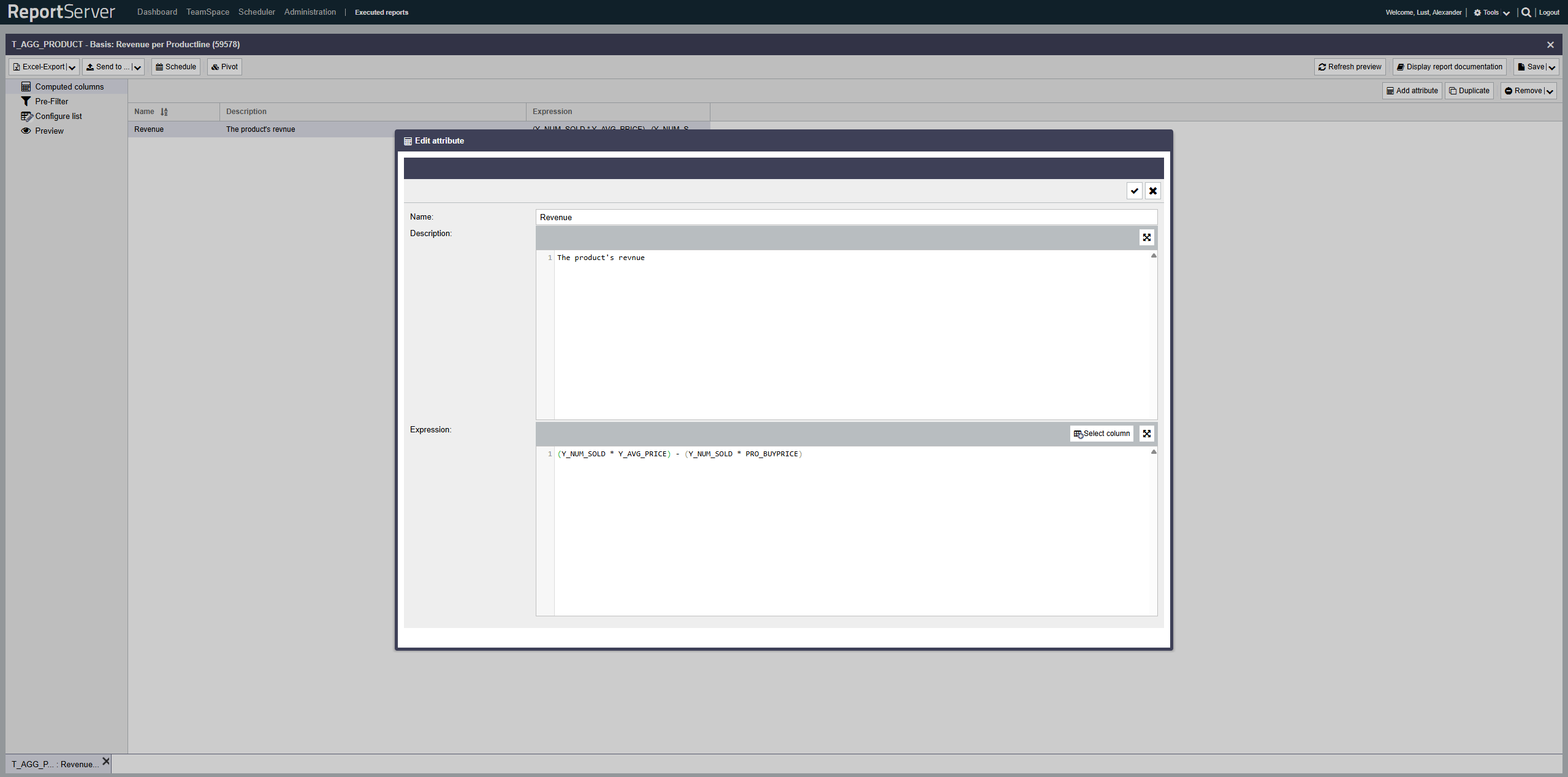
Die Angabe der Berechnungsvorschrift erfolgt in Form eines SQL-Ausdrucks, der direkt auf der Datenbank ausgeführt wird. Dies bedeutet insbesondere, dass die verfügbaren Ausdrücke von der eingesetzten Datenbank abhängig sind. Welche Funktionen im Detail zur Verfügung stehen, erfahren Sie von Ihrem Administrator. Dieser Abschnitt erläutert nur einige allgemeine Möglichkeiten.
Haben Sie in ReportServer ein berechnetes Feld definiert, so können Sie dies anschließend genau wie jede andere Spalte in Ihren Auswertungen nutzen. Auch berechnete Felder müssen Sie, damit diese im Ergebnis angezeigt werden, im Aspekt Listenkonfiguration Ihrer Auswertung hinzufügen.
Die Konfiguration berechneter Felder erfolgt im Aspekt Berechnete Felder. Hier können Sie Felder anlegen und ihre Definition bearbeiten. Der von Ihnen vergebene Name dient als Name für die erstellte Spalte und muss daher den Vorgaben für Spaltennamen (alphanumerisch, keine Leerzeichen) genügen. Spaltennamen müssen eindeutig sein.
SQL bietet eine Vielzahl an Möglichkeiten ein Feld zu definieren, die den Rahmen dieser Anleitung deutlich übersteigen. Nichts desto trotz hier einige Codebeispiele die häufig in berechneten Feldern genutzt werden.
Im folgenden gehen wir von einer Tabelle mit folgenden Spalten aus
A, B: Spalten mit Text
C, D: Spalten mit ganzen Zahlen
Für einfache Berechnungen können Sie die Grundrechenarten verwenden, z.B.
C + D als Definition für ein Feld mit der Summe beider Spalten.
Die Konkatenation, das Aneinanderfügen zweier Textspalten, erfolgt in der Regel mit dem ||-Operator. Auch der Operator +, oder der Aufruf von CONCAT(A, B) sind üblich.
Mit CASE-Ausdrücken können Bedingungen formuliert werden. Zum Beispiel können Werte so abhängig von Ihrer Größe klassifiziert werden.
CASE
WHEN SPALTE < 500 THEN 1
WHEN SPALTE < 1000 THEN 2
WHEN SPALTE < 2000 THEN 3
WHEN SPALTE < 3000 THEN 4
ELSE 0
ENDBeachten Sie bei CASE-Ausdrücken, dass die Anweisung der ersten zutreffenden Bedingung gewählt wird unabhängig davon, ob evtl. auch eine später folgende Bedingung zutrifft. Die Rückgabewerte aller Bedingungen müssen vom gleichen Datentyp sein.
Dynamische Listen können neben den bekannten Exportformaten, wie EXCEL oder CSV, auch direkt in vordefinierte Templates eingefügt werden. In diesem Abschnitt stellen wir die Grundfunktionalität vor.

Templates werden bei der Ausführung einer dynamischen Liste im Aspekt Listenkonfiguration über die Schaltfläche verwaltet. In dem sich öffnenden Dialog sehen Sie eine Liste der derzeit für diese Variante existierenden Templates. Über die Werkzeugleiste können Sie neue Templates hinzufügen oder existierende zur Bearbeitung herunterladen.
Templates haben neben Namen und Beschreibung auch einen Typ. Zur Zeit stehen folgende Typen zur Verfügung:
| jXLS | Erlaubt die Definition von Templates in Microsoft Excel. |
| XDoc | Erlaubt die Definition von Templates in Microsoft Word. |
| Velocity | Erlaubt die Definition von Text-Templates. |
| XSLT | Erlaubt die Definition von XML-Templates. |
Wenn Sie ein neues Template angelegt haben, können Sie anschließend die entsprechende Datei hochladen. Im folgenden geben wir für jeden Templatetype ein Beispiel an. Eine vollständige Dokumentation der Funktionalität würde jedoch den Rahmen dieses Handbuchs sprengen. Weiterführende Dokumentation zu den einzelnen Templateformaten finden Sie unter:
| JXLS | https://jxls.sourceforge.net |
| XDocReport | https://github.com/opensagres/xdocreport |
| Velocity | https://velocity.apache.org/ |
| XSLT | https://www.w3.org/TR/xslt |
Durch Integration der JXLS Template Engine in ReportServer, ist es möglich auch anspruchsvoll formatierte Excel Arbeitsblätter direkt aus der Reporting-Plattform heraus zu erzeugen. Der JXLS-Ansatz ist, das Template, welches das Aussehen des eigentlichen Dokuments bestimmt, selbst ein Excel Arbeitsblatt ist und somit direkt mit Microsoft Excel erstellt und bearbeitet werden kann. Mit spezielle Anweisungen im Template-Dokument wird gesteuert wo Daten im Template eingefügt werden.
Beispiele zu JXLS in ReportServer können Sie hier finden: https://github.com/infofabrik/reportserver-samples/tree/main/src/net/datenwerke/rs/samples/templates/jxls.
Eine detaillierte Beschreibung aller Funktionen von JXLS würde den Rahmen dieses Dokuments sprengen, daher folgt hier nur eine kurze Erläuterung der Grundlagen. JXLS2 wird im ReportServer unterstützt und wird hier kurz beschreiben. Die Legacy JXLS1 Version wird nicht unterstützt.
Eine vollständige JXLS2-Dokumentation finden Sie auf der JXLS-Projektseite unter https://jxls.sourceforge.net. Hier zeigen wir einen Überblick über die wichtigsten Komponenten für die Arbeit mit ReportServer.
In JXLS2 (https://jxls.sourceforge.net) definieren Sie die JXLS2-Befehle über Excel-Kommentare. Die JXLS2-Engine analysiert diese Kommentare und transformiert die Vorlage entsprechend. Hier zeigen wir Ihnen ein einfaches Beispiel einer Vorlage und erläutern Ihnen kurz deren Komponenten. Weitere Informationen finden Sie im Administrationshandbuch (JXLS-Berichte) und in der JXLS2-Dokumentation.
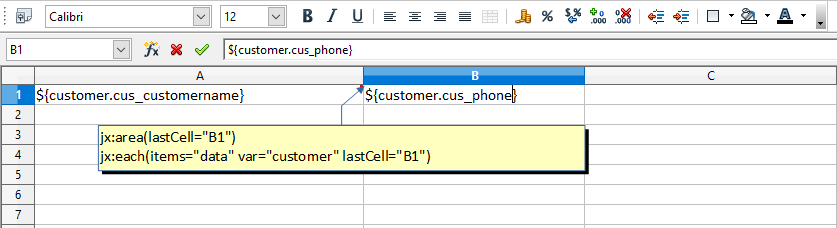
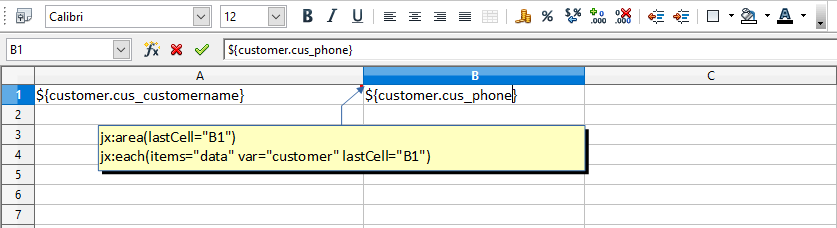
Die Zelle A1 enthält einen Excel-Kommentar mit dem folgenden Text: jx: area (lastCell = "B1"). Es definiert die Grenzen unserer Vorlage als A1:B1. Es enthält auch einen Jxls Each-Befehl mit dem folgenden Text: jx: each (items = "data" var = "customer" lastCell = "B1"). Der Each-Befehl iteriert die Sammlung von Objekten in der ''data''-Variable und druckt die entsprechenden Informationen. Der Hauptbereich des Each-Befehls ist A1:B1 (definiert durch das lastCell-Attribut). Dies bedeutet, dass die Zellen mit jedem neuen Kundenobjekt im Kontext geklont und verarbeitet werden.
Beachten Sie, dass ''data'' die von der dynamischen Liste ausgewählten Daten enthält. Dies wird automatisch von ReportServer bereitgestellt und kann direkt in JXLS-Vorlagen verwendet werden, wenn es als Vorlage für die dynamische Liste verwendet wird.
jx:area(lastCell="B1")
jx:each(items="data" var="customer" lastCell="B1")
${customer.cus_customername} | ${customer.cus_phone}Beachten Sie, dass Sie die Felder in Kleinbuchstaben eingeben müssen, damit diese von der JXLS-Engine korrekt zugeordnet werden.
Da wir nun gelernt haben wie die templates als Vorlage generell im Reportserver funktionieren, wollen wir uns einem Beispiel dazu widmen.
Um nun ein praktisches Gefühl der Nutzung von templates in ReportServer nachzukommen, wollen wir hier nun ein praktisches Beispiel der templates mit JXLS illustrieren.
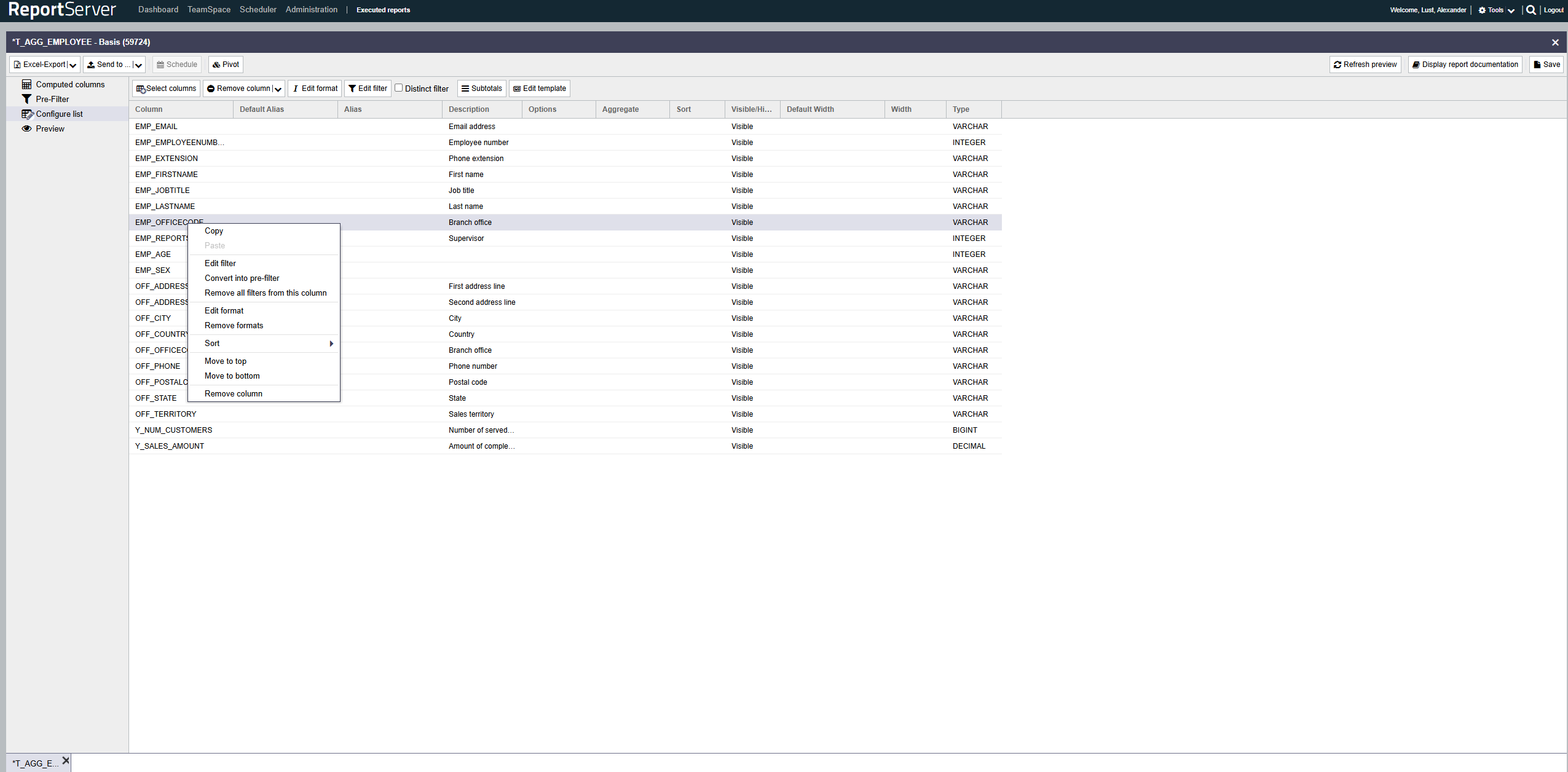
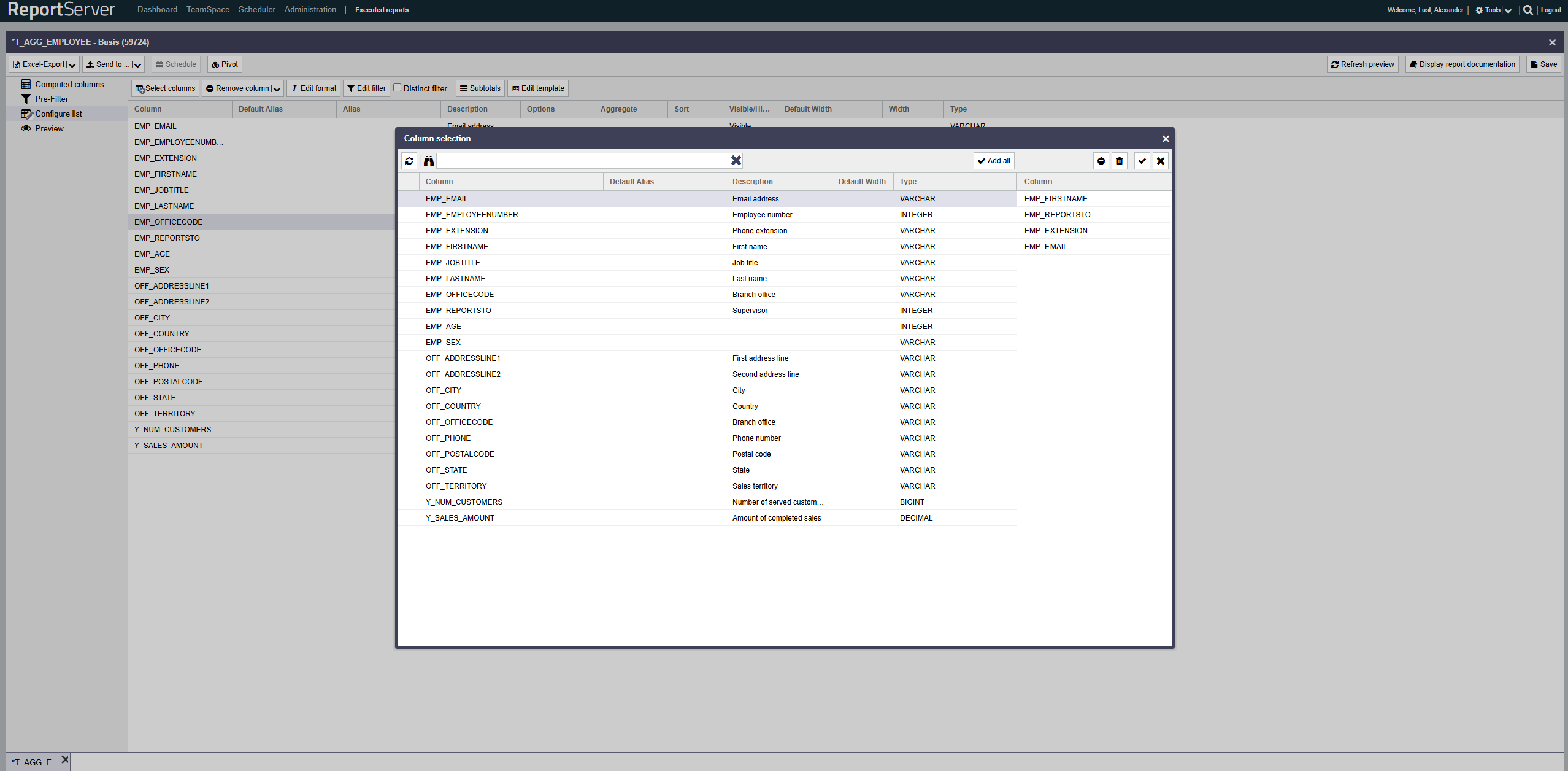
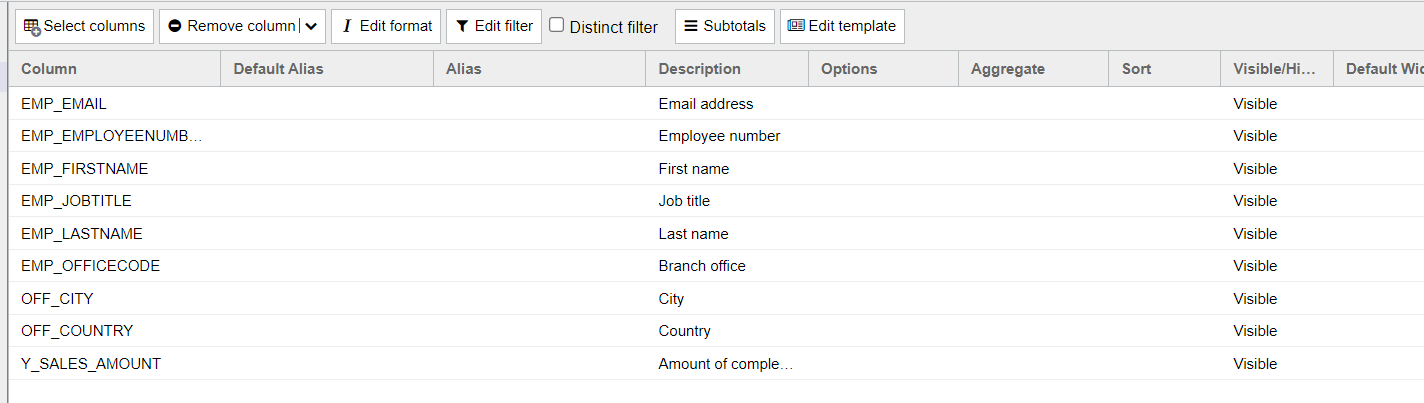
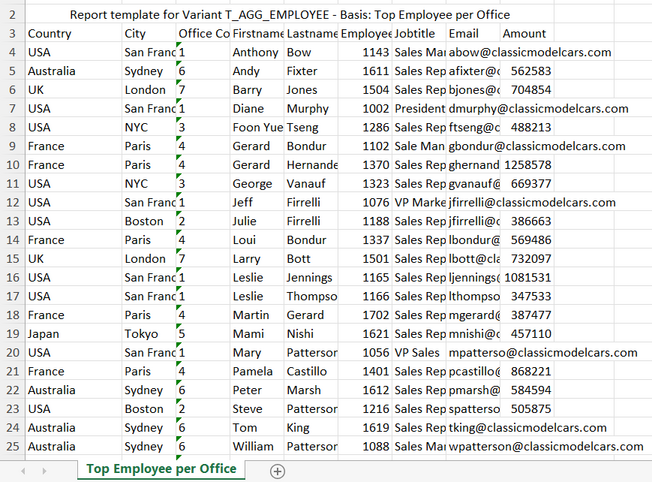
Zu erst kreieren wir uns eine dynamische Liste und wählen dabei die Spalten aus die wir uns via dem template in templatedefinierter Form zurückgeben wollen. In diesem Beispiel gehen wir vom Beispielreport ''T_AGG_EMPLOYEE'' aus und wählen die Spalten ''EMP_EMAIL'', ''EMP_EMPLOYEENUMBER'', ''EMP_FIRSTNAME'', ''EMP_JOBTITLE'', ''EMP_LASTNAME'', ''EMP_OFFICECODE'', ''OFF_CITY'', ''OFF_COUNTRY'' und ''Y_SALES_AMOUNT'' aus.
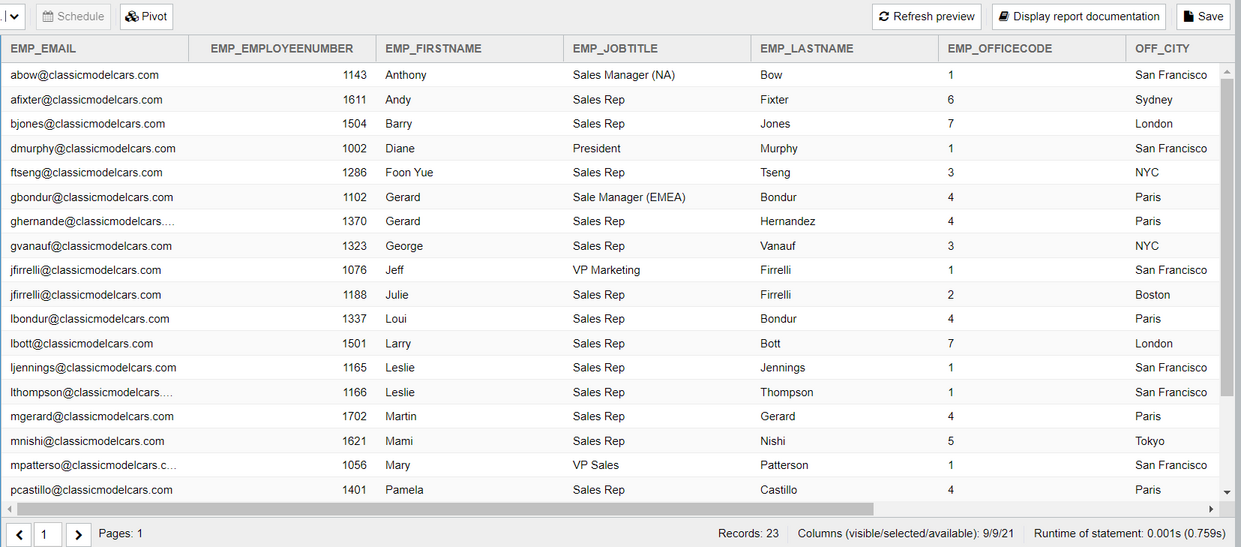
Hier sehen wir dann über eine Vorschau all die Spalten mit Ihren Daten, die wir für wichtig erachten pro Datensatz jeweils.
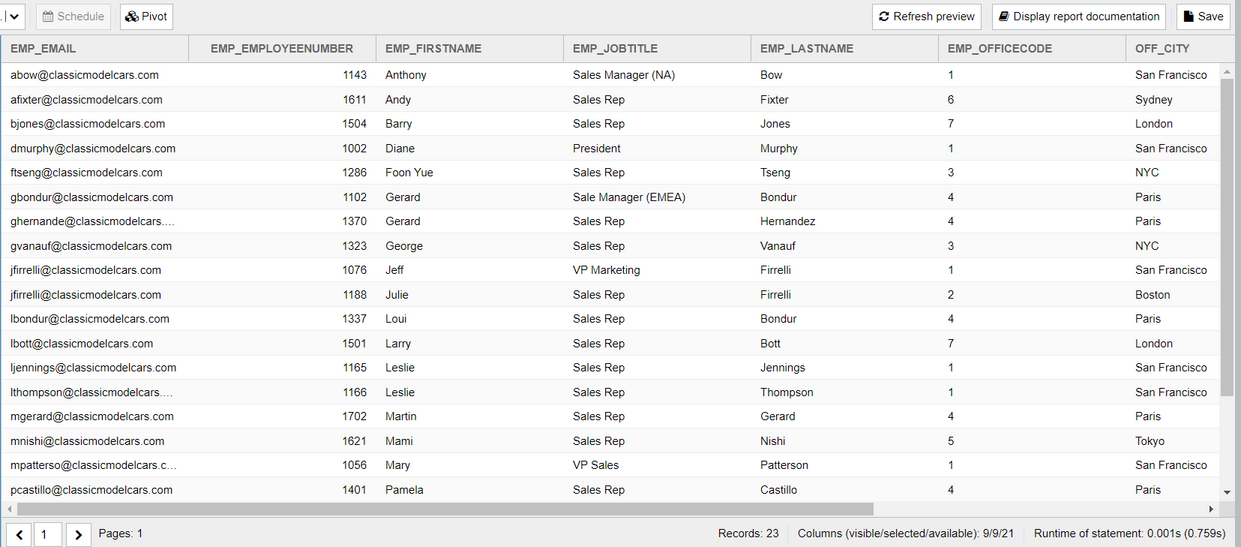
Nun müssen wir die Template erstellen. Dies erfolgt am Besten mit Excel und kann in etwa anhand eines solchen offiziellen Beispiels erfolgen: https://jxls.sourceforge.net/reference/each_command.html. Bezogen auf unserem Beispiel könnte man sich die Templates hier: https://github.com/infofabrik/reportserver-samples/tree/main/src/net/datenwerke/rs/samples/templates/jxls/jxlsdynamiclist herunterladen.
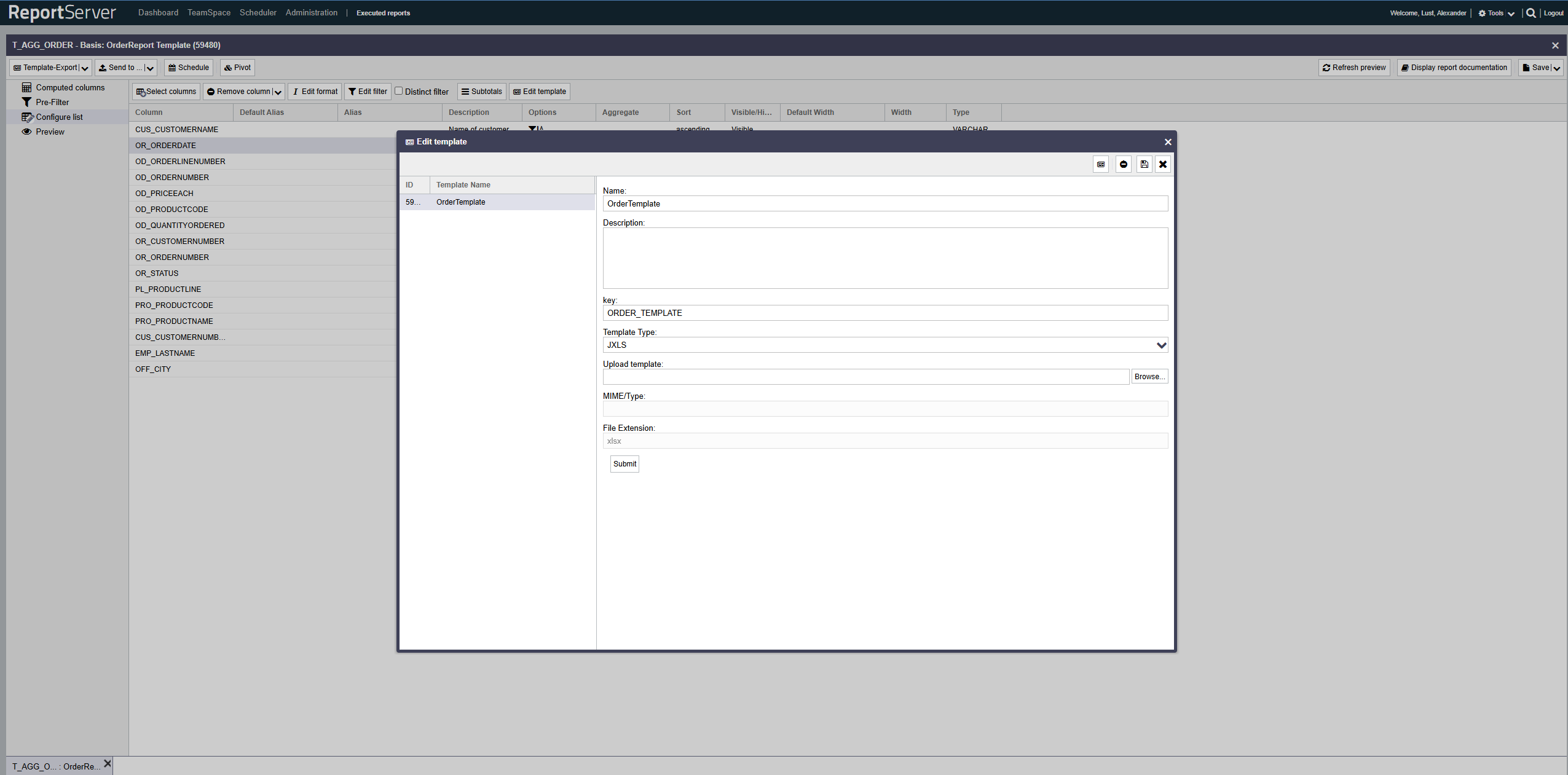
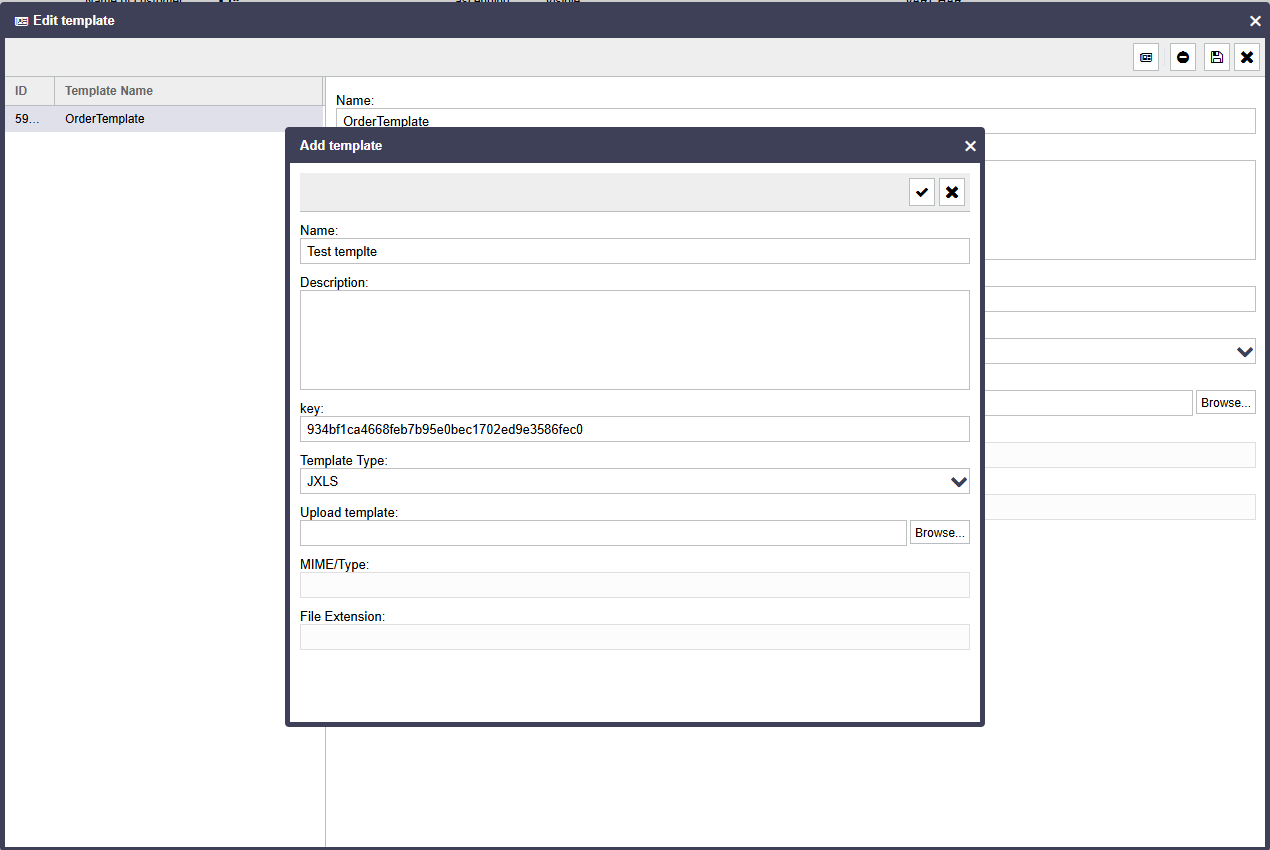
Nun muss nur noch die Template auf den ReportServer geladen werden. Dafür folgt man diesen Anweisung in genau dieser beschriebenen Reihenfolge:
- Bitte auf Configure list klicken
- Auf den button Edit template klicken
- Dann auf Add template gehen
- Das Format als JXLS Format im pulldown menü Template Type angeben
- Nun nur noch die vorrangegangene excel Datei hochladen

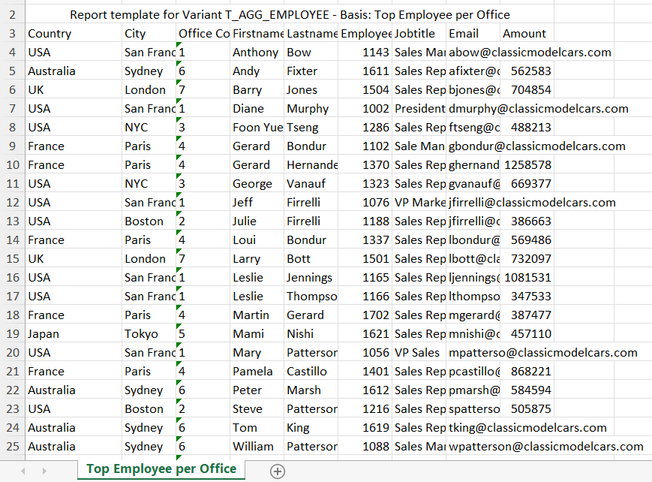
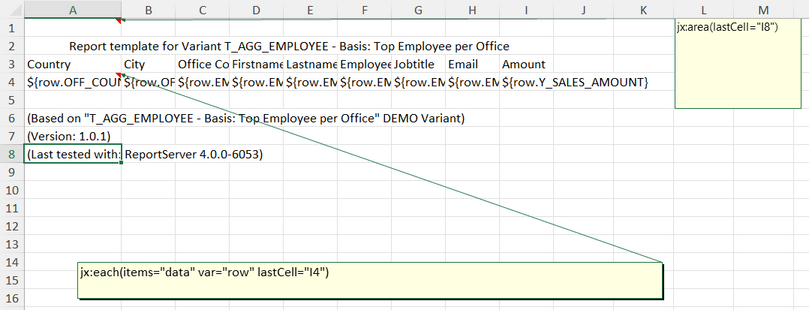
Nun sollte die dynamische Liste ein neues Exportformat ermöglichen das sich Template nennt. Dank des vorrangegangenen Beispieltemplates sollte die Exceldatei folgende Ausgabe erzeugen.
Velocity https://velocity.apache.org/ ist eine Template-Sprache für Textdokumente. Hiermit können Sie jegliche Ausgabeformate erzeugen, die einfachen ASCII-Text als Dateiformat verwenden.
Sie können Velocity Beispiele in ReportServer hier finden: https://github.com/infofabrik/reportserver-samples/tree/main/src/net/datenwerke/rs/samples/templates/velocity.
Hallo Welt, dies ist eine Velocity Template!Mit der Ersetzung $data kann auf die einzelnen Datensätze zugegriffen werden (das Beispiel setzt voraus, dass die dynamische Liste das Feld "CUS_CUSTOMER_NAME" enthält).
Kundenliste:
Customer List:
----------------------------------------------------------
#foreach ( $customer in $data )
$customer.CUS_CUSTOMERNAME
#endDieses Template kann auch von unserem reportserver-samples GitHub heruntergeladen werden: https://github.com/infofabrik/reportserver-samples/tree/main/src/net/datenwerke/rs/samples/templates/velocity
Sie können Ihre Berichtsparameterwerte verwenden/anzeigen, indem Sie das verfügbare ''parameters''-Objekt verwenden. Wenn Ihr Bericht z. B. einen Parameter ''myparameter'' hat, können Sie mit folgendem darauf zugreifen:
$parameters.myparameterAußerdem können Sie auf alle speziellen Parameter zugreifen, die hier erklärt werden: https://reportserver.net/en/guides/admin/chapters/using-parameters/, indem Sie das verfügbare ''meta''-Objekt verwenden. Das folgende Beispiel zeigt den Namen des Berichts an:
$meta._RS_REPORT_NAME.valueBeachten Sie dass, im Unterschied zu den oben erläuterten Berichtsparametern, ''value'' benötigt wird, um die Werte der speziellen Parameter abzurufen.
XDocReport https://github.com/opensagres/xdocreport bringt die Velocity Template-Sprache mit Microsoft Word zusammen.
Sie können XDocReport Beispiele in ReportServer hier finden: https://github.com/infofabrik/reportserver-samples/tree/main/src/net/datenwerke/rs/samples/templates/xdoc.
Um Template Befehle, wie z.B.
#foreach ( $customer in $data )zu verwenden müssen Sie diese in sogenannten einbetten. Gehen Sie hierzu auf "Einfügen/Schnellbausteine/Feld..." und wählen anschließend aus der Kategorie Seriendruck das Feld MergeField aus. In dem Eingabefeld unter Feldfunktionen wird dann der Befehl eingetragen. So könnte man das obige Velocity Beispiel z.B. wie folgt abbilden, wobei MERGEFELD[XX] für einen Befehl als Mergefeld steht.
Alle Kunden:
MERGEFIELD[#foreach($customer in $data)]
MERGEFIELD[$customer.CUS_CUSTOMERNAME]
MERGEFIELD[#end]Im folgenden Screenshot sehen Sie das resultierende Template in Word. Dieses und die Ergebnisse des Template-Ausführung kann auch von unserem reportserver-samples GitHub heruntergeladen werden: https://github.com/infofabrik/reportserver-samples/tree/main/src/net/datenwerke/rs/samples/templates/xdoc

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Sie können Ihre Berichtsparameterwerte verwenden/anzeigen, indem Sie das verfügbare ''parameters''-Objekt verwenden. Wenn Ihr Bericht z. B. einen Parameter ''myparameter'' hat, können Sie mit folgendem darauf zugreifen:
MERGEFIELD[$parameters.myparameter]Außerdem können Sie auf alle speziellen Parameter zugreifen, die hier erklärt werden: https://reportserver.net/en/guides/admin/chapters/using-parameters/, indem Sie das verfügbare ''meta''-Objekt verwenden. Das folgende Beispiel zeigt den Namen des Berichts an:
MERGEFIELD[$meta._RS_REPORT_NAME.value]Beachten Sie dass, im Unterschied zu den oben erläuterten Berichtsparametern, ''value'' benötigt wird, um die Werte der speziellen Parameter abzurufen.
Um XML basierend auf dynamischen Listen zu erstellen, können Sie XSLT (Extensible Stylesheet Language Transformations) verwenden.
Die Eingangsdaten für die XSL-Transformation ist der HTML Export von ReportServer. Im folgenden stellen wir eine einfache generische Transformation dar, die die Daten in ein einfaches XML Format überführt indem zunächst alle Attribute aufgezählt werden, und dann pro Datensatz ein "record"-Element eingefügt wird:
Dieses Beispiel finden Sie hier: https://github.com/infofabrik/reportserver-samples/blob/main/src/net/datenwerke/rs/samples/templates/xslt/.
<?xml version="1.0"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xhtml="http://www.w3.org/1999/xhtml">
<xsl:template match="/">
<myXmlFormat>
<xsl:apply-templates select="//xhtml:tr"/>
</myXmlFormat>
</xsl:template>
<!-- attributes -->
<xsl:template match="xhtml:thead/xhtml:tr">
<attributes>
<xsl:apply-templates mode="attributes" />
</attributes>
</xsl:template>
<xsl:template match="xhtml:th" mode="attributes">
<attribute>
<xsl:value-of select="."/>
</attribute>
</xsl:template>
<!-- values -->
<xsl:template match="xhtml:tbody/xhtml:tr">
<records>
<xsl:apply-templates mode="values" />
</records>
</xsl:template>
<xsl:template match="xhtml:td" mode="values">
<record>
<xsl:value-of select="."/>
</record>
</xsl:template>
</xsl:stylesheet>Das Ergebnis könnte dann beispielsweise wie folgt aussehen:
<?xml version="1.0" encoding="UTF-8"?>
<myXmlFormat
xmlns:xhtml="http://www.w3.org/1999/xhtml">
<attributes>
<attribute>Country</attribute>
<attribute>City</attribute>
<attribute>Office Code</attribute>
<attribute>Firstname</attribute>
<attribute>Lastname</attribute>
<attribute>Employee Nr</attribute>
<attribute>Jobtitle</attribute>
<attribute>Email</attribute>
<attribute>Amount</attribute>
</attributes>
<records>
<record>USA</record>
<record>San Francisco</record>
<record>1</record>
<record>Leslie</record>
<record>Jennings</record>
<record>1165</record>
<record>Sales Rep</record>
<record>ljennings@classicmodelcars.com</record>
<record>1.081.530,54</record>
</records>
<records>
<record>USA</record>
<record>NYC</record>
<record>3</record>
<record>George</record>
<record>Vanauf</record>
<record>1323</record>
<record>Sales Rep</record>
<record>gvanauf@classicmodelcars.com</record>
<record>669.377,05</record>
</records>
</myXmlFormat>