
Stars, Spreadsheets and the Dynamic List
This is the second post in the Dynamic List series and here we dig a bit deeper into the rational behind Dynamic Lists. We discuss data warehouse design and spreadsheets and how the Dynamic List fits into both to then discuss how to optimize your data warehouse design for Dynamic Lists.
This is the second post in the Dynamic List series. So far the following posts are available in this series.
Stars and Snowflakes
When you think about data warehouse design what usually comes to mind is a star or snowflake schema. Star and snowflake schemas are named after the outline of their corresponding ER diagrams where a single FACT table is in the center which is surrounded by DIMENSION tables.
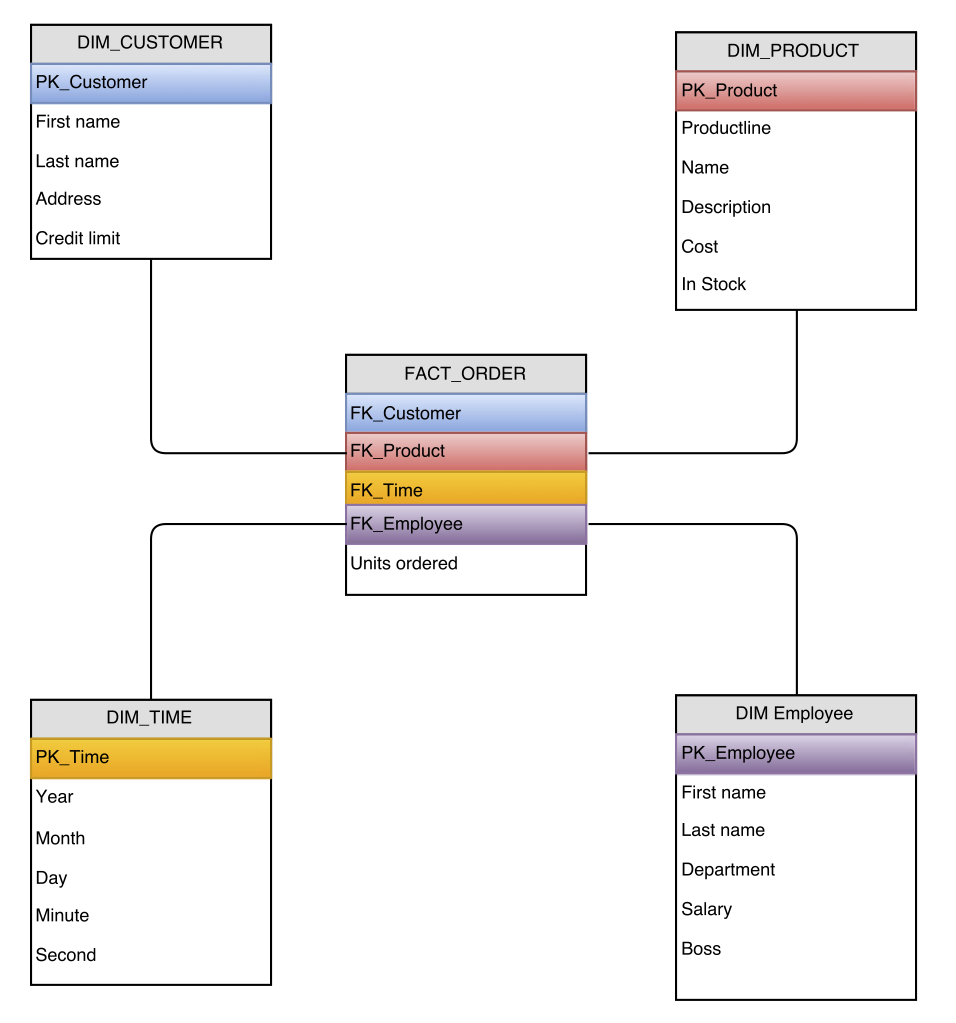
Coming back to our example of the toy manufacturer, we could model a star schema around the orders placed by customers. Thus we’d place a FACT_ORDER table in the very center which contains measurements such as the number of ordered items as well as foreign keys for referencing all the entities that are involved in an order: The product that was ordered, the time when the order was placed, the customer that placed the order, the employee that processed it, etc.
Let’s look at the benefits of using star schemas for data warehouses. According to Wikipedia:
Star schemas are denormalized, meaning the normal rules of normalization applied to transactional relational databases are relaxed during star schema design and implementation. The benefits of star schema denormalization are:
- Simpler queries […]
- Simplified business reporting logic […]
- Query performance gains […]
- Fast aggregations […]
So to sum up, by removing normalization (the process of ensuring that data is never duplicated and only ever stored in a single place) as compared to production systems (i.e., the system where the employee processes the order) we gain: simpler queries for reporting, simpler logic, better query performance and faster aggregations. This sounds fantastic and, indeed, is true … to some extent.
To get interesting data from a star schema we always need to join one or more dimensions to the fact table. Consider the following query:
SELECT DISTINCT C.FirstName, C.LastName, C.Address FROM FACT_ORDERS
INNER JOIN DIM_CUSTOMER C ON (FACT_ORDERS.FK_Customer = C.PK_Customer),
INNER JOIN DIM_PRODUCT P ON (FACT_ORDERS.FK_Product = P.PK_Product)
WHERE P.name = "Classic Cars"
Now this should return all the customers that have ever bought a Classic Car model. While the above query might be considered simple in the eyes of the SQL veteran it is definitely complex for anybody else. Indeed, explaining star schemas and star queries (the above would be considered a star query) is highly non-trivial. On the other hand, when working with such schemas, for example, through OLAP cubes it is necessary for the user to understand how these underpinnings work. This is probably one of the reasons why usually end users are not given direct access to the data (or the OLAP cube) but can only access predefined reports where the options to explore and visualize the data are predefined by IT. In other words we could go so far and say that
the complexity of star schemas leads to an undesirable division of responsibilities. Those that know and need the data don’t get direct access to it; those that have direct access often do not need the data.
Of course, star schemas and OLAP tools have their specific use cases. However, they are often used in situations where they cannot properly play to their strengths. With the Dynamic List we have created a reporting engine that takes the idea of the star schema to the next level and overcomes many of the complexities that are inherent to stars and OLAP. But before we get to the Dynamic List and how it fits into stars, let’s have a look at spreadsheets.
Spreadsheets
Tables have been used for hundreds of years to record data and most of us have quite a good intuition when it comes to working with and extracting data from tables. This can also be seen by the success of spreadsheet programs such as Microsoft Excel or Open Office Calc. What company today could exist without spreadsheets?
While spreadsheets are immensely powerful and popular they can also be rather problematic. Spreadsheets intertwine data and metadata. That is, they contain the actual data records as well as information about how they are to be visualized (i.e., sorted, filtered or aggregated). The result is that it is very difficult to update the data within a spreadsheet without having to redo the entire thing. Furthermore (and maybe worse), spreadsheets can be terribly difficult to understand: whoever tried to debug and understand several lines of Excel formulas would surely agree. These problems led Tim Worstall exclaim on Forbes
Microsoft’s Excel Might Be The Most Dangerous Software On The Planet
ReportServer’s Dynamic List takes a leaf out of the spreadsheet book in that it is based on a table: Anybody who understands tables understands basic spreadsheets and anybody who understands basic spreadsheets understands the basics of the Dynamic List (and anybody who understands advanced spreadsheets such as Pivot tables understands the more advanced Dynamic List functionality). The Dynamic List, however, is not a spreadsheet but rather the metadata of a spreadsheet. When you are working on a Dynamic List what you are working on are filters, aggregations, formats, etc. but you are working on these, completely independent from the actual data. The actual data only comes into play when you run the Dynamic List. Only then is the metadata that you have defined thrown onto the actual data coming from some datasource to create the final report.
This solves the first problem of spreadsheets: With Dynamic Lists it is trivial to update the data. Whenever you run the Dynamic List the up-to-date data is used to generate the report. The Dynamic List itself is merely metadata.
The second spreadsheet problem is that they may become terribly complex and it is very difficult to understand spreadsheets made by others (or indeed, spreadsheets one created oneself; just give it a week). For this, ReportServer offers an intriguingly simple solution. For every Dynamic List (and, indeed, for any report) ReportServer provides a documentation which describes the metadata, i.e., the configuration. Consider the Dynamic List created in the first part of this series. Here Bob created a Dynamic List consisting of three attributes and a filter. The corresponding report documentation was:

Given this documentation it is easy to extract what the report contains: three attributes (customer number, name and productline) filtered by product (only Classic Cars) and sorted by customer name. Additionally, duplicate rows are removed.
Second problem: solved.
The Dynamic List and Stars
So what do Dynamic Lists have to do with star schemas? The above sample schema
allows to answer questions that revolve around orders. So how can we create a Dynamic List that is able to answer the very same questions but at the same time benefit from the simple “Table Model” of spreadsheets?
The idea behind star schemas is to denormalize data in order to allow for “simpler queries and better (read) performance”. There is, however, one extra level of denormalization that is left open. Stars have a FACT table in the center and DIMENSION tables floating around it. For any report, these need to be first combined in some form. The idea behind the Dynamic List is that this combination is “precomputed” and that the Dynamic List is based on the (possibly very large) table resulting from joining all the dimensions to the FACT table. In other words, the base table for the Dynamic List could be described as
SELECT C.*, P.*, T.*, E.*, FACT_ORDERS.* FROM FACT_ORDERS
INNER JOIN DIM_CUSTOMER C ON (FACT_ORDERS.FK_Customer = C.PK_Customer),
INNER JOIN DIM_PRODUCT P ON (FACT_ORDERS.FK_Product = P.PK_Product),
INNER JOIN DIM_TIME T ON (FACT_ORDERS.FK_Time = T.PK_TIME),
INNER JOIN DIM_EMPLOYEE E ON (FACT_ORDERS.FK_Employee = E.PK_Employee)
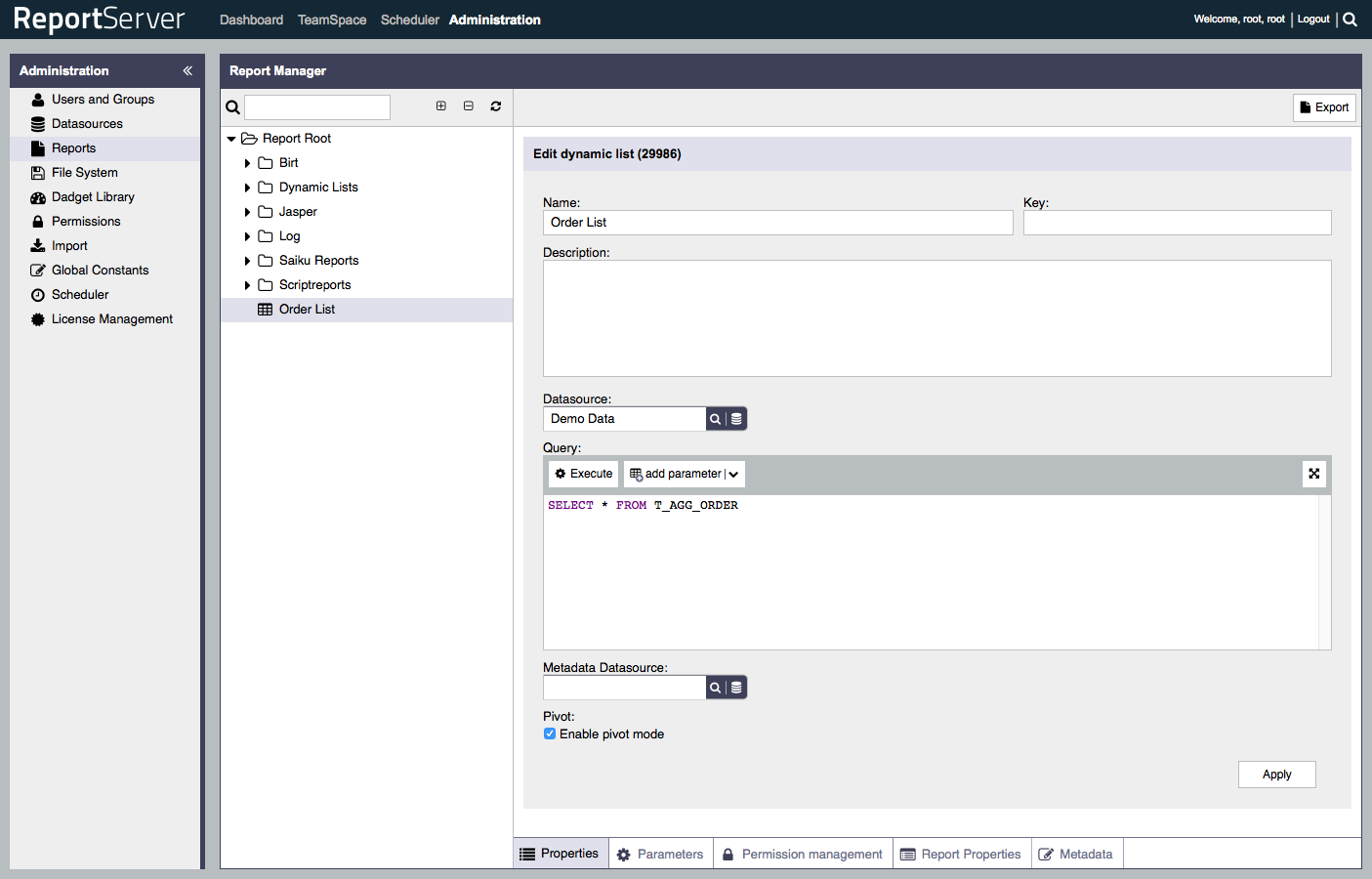
When configuring a Dynamic List one could indeed use the above query. Remember that the only real configuration necessary in the backend is to define the SQL that describes a base query (see the following definition of the Dynamic List from the first part of this series):
This would yield the desired result: the resulting Dynamic List is powerful enough to answer all the queries that could have been answered by directly working with the star schema. However, performance-wise this would not produce optimal results. The reason is that ReportServer doesn’t know or care about the underlying schema. All it cares about is the base table defined by the query. This makes Dynamic Lists very easy to maintain since changes in the underlying warehouse do not affect the Dynamic List as long as the query is still functioning. The downside is that ReportServer cannot leverage the underlying structure. Consider the questions as before “list all customers that have ordered Classic Cars”. When directly working with the star schema one would try to formulate SQL that is understood by the Query Optimizer of the underlying database system to first filter the product dimension and only then perform the join operation. This is because join operations are rather expensive and require, for example, to sort all the involved tables. Thus, the smaller the tables that are joined, the faster the query execution.
ReportServer on the other hand, not knowing about the underlying structure, would produce a query such as the following
SELECT DISTINCT C.FirstName, C.LastName, C.Address FROM(
SELECT C.*, P.*, T.*, E.*, FACT_ORDERS.* FROM FACT_ORDERS
INNER JOIN DIM_CUSTOMER C ON (FACT_ORDERS.FK_Customer = C.PK_Customer),
INNER JOIN DIM_PRODUCT P ON (FACT_ORDERS.FK_Product = P.PK_Product),
INNER JOIN DIM_TIME T ON (FACT_ORDERS.FK_Time = T.PK_TIME),
INNER JOIN DIM_EMPLOYEE E ON (FACT_ORDERS.FK_Employee = E.PK_Employee)
) InnerQ WHERE P.name = "Classic Cars"
One might hope that query optimizers are clever enough to understand that one could first do the filtering and then the joining but most databases would execute the above query by first computing the inner query and only then performing the filter operation. So what can we do? The answer is: degenerate stars.
Degenerate Stars
As mentioned before the star schema is the result of a denormalization process that stops with one level to spare: a fact table in the center and dimension tables around it. The optimal strategy for the Dynamic List, however, is to take this final step and produce a fully denormalized view of the data. This is sometimes called a degenerate aggregate table. We call it a degenerate star. Obtaining these from a star schema is trivial, simply precompute the table that results from joining all dimensions to the fact table
CREATE TABLE T_AGG_ORDER AS (
SELECT C.*, P.*, T.*, E.*, FACT_ORDERS.* FROM FACT_ORDERS
INNER JOIN DIM_CUSTOMER C ON (FACT_ORDERS.FK_Customer = C.PK_Customer),
INNER JOIN DIM_PRODUCT P ON (FACT_ORDERS.FK_Product = P.PK_Product),
INNER JOIN DIM_TIME T ON (FACT_ORDERS.FK_Time = T.PK_TIME),
INNER JOIN DIM_EMPLOYEE E ON (FACT_ORDERS.FK_Employee = E.PK_Employee)
)
The prefix T_AGG_ is the one that we use when setting up data warehouses and stands for aggregate table (which can be a bit confusing as technically the table doesn’t contain preaggregated data). Now, when you create a Dynamic List, the query to use is simply
SELECT * FROM T_AGG_ORDERAll the heavy join operations have now been precomputed and you get optimal performance from your Dynamic List. If you additionally add indexes on attributes that are likely to be used as filters, you can further optimize the user experience. So what is the downside? The short answer is: usually there is none. The only real downside is that having a completely denormalized view increases the amount of storage space needed by your database. As storage space is relatively cheap this is, however, hardly ever a concern.
This is it for this blog post. Jumping ahead we note that the degenerate star approach to data warehouses brings to mind an intriguing optimization possibility for Dynamic Lists: so called column stores which we discuss in a later part of this series.